Modern analytics environments are built as end-to-end data pipelines, not isolated tools.
Data starts in operational databases, flows through ETL processes, is transformed in data warehouses, and finally reaches BI datasets and reports used by the business. Every layer depends on the one below it — and every change propagates downstream.
- A column is renamed in a database.
- An ETL transformation is optimized.
- A warehouse table is refactored.
- A BI calculation is updated.
And suddenly the most important question becomes:
“If we change this — what will break across the entire data flow?”
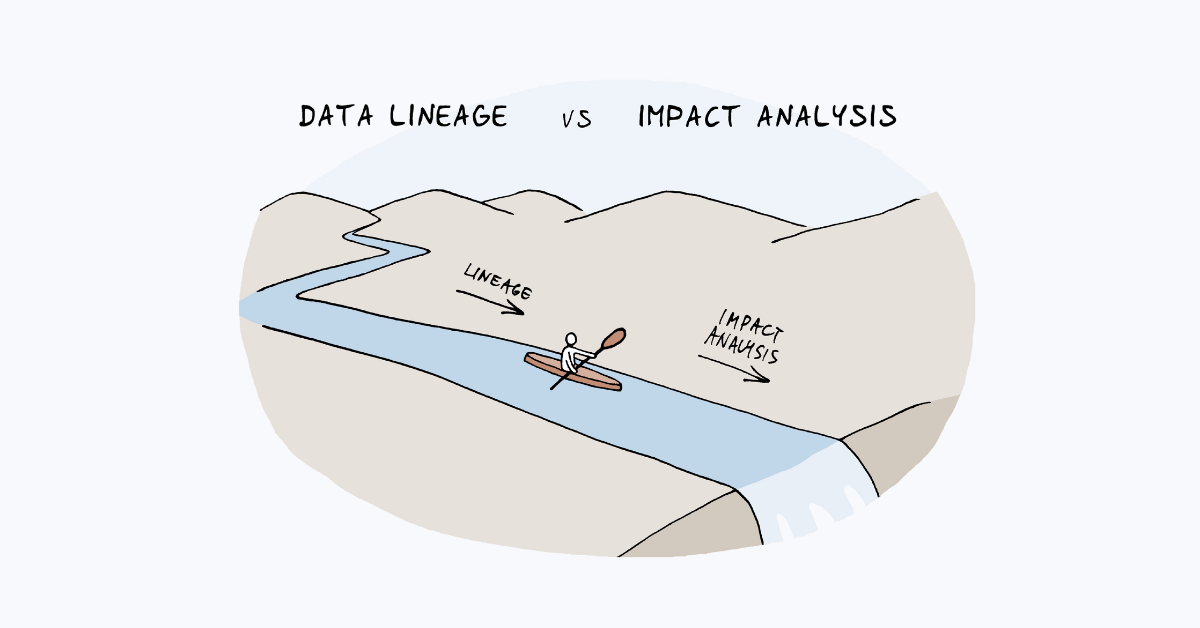
This is exactly what end-to-end impact analysis addresses.
Impact analysis makes the full data path visible — from source databases, through ETL pipelines, all the way to BI reports — so teams can understand the consequences of change before deploying it to production.
In this guide, you’ll learn:
- what end-to-end impact analysis really means in analytics,
- why it fails in most organizations,
- how lineage enables reliable impact analysis,
- and how tools like Dataedo make impact analysis practical across databases, ETL, and BI.
What Is End-to-End Impact Analysis in Analytics?
End-to-end impact analysis is the ability to identify all downstream dependencies affected by a change anywhere in the analytics stack — before that change is applied.
In practice, it answers questions such as:
- Which ETL packages use this database column?
- Which warehouse tables are affected by this transformation?
- Which BI datasets, measures, and reports depend on this field?
- Who owns those assets?
- How critical are they for the business?
Without impact analysis, teams make changes in isolation — often discovering problems only after users report broken dashboards or inconsistent KPIs.
Why Impact Analysis Is Hard in Data Pipelines
In practice, most analytics teams don’t lack discipline — they lack visibility.
When dependencies across databases, ETL, and BI are invisible, impact analysis becomes guesswork.
Analytics stacks are inherently complex and layered:
- Databases (SQL Server, PostgreSQL, ERP, CRM)
- ETL pipelines (SSIS, ADF, custom SQL)
- Data warehouses
- Semantic layers (SSAS, Power BI datasets)
- BI reports and dashboards
Each layer introduces:
- renaming and reshaping of data,
- business logic,
- aggregations and calculations,
- reused objects across multiple downstream assets.
Over time:
- documentation becomes outdated,
- ownership becomes unclear,
- dependencies become invisible.
This is why impact analysis is often skipped — not because teams don’t care, but because they lack visibility.

Common Situations That Require Impact Analysis
Impact analysis is not an edge case. It’s required in everyday analytics work.
1. Database Schema Changes
A column is renamed, removed, or its data type changes in a source database.
Without impact analysis:
- ETL packages may fail or silently load incorrect data,
- warehouse tables may contain nulls or inconsistent values,
- BI reports may show misleading results.
With impact analysis:
- you instantly see which ETL processes, warehouse tables, and BI reports depend on that column.
2. ETL Logic Changes
An engineer modifies a transformation, lookup, or incremental load rule.
Questions immediately arise:
- Which tables will change?
- Which reports rely on those tables?
- Is this logic reused elsewhere?
Impact analysis prevents local ETL changes from creating global analytics issues.
3. BI Model and KPI Changes
A measure definition is updated.
A KPI calculation is corrected.
Without impact analysis:
- different reports may show different numbers,
- reconciliation moves back to Excel,
- trust in dashboards erodes.
Impact analysis shows:
- where a calculation is used,
- which reports will change,
- which stakeholders must be informed.
4. Platform Modernization and Migration
Typical examples:
- SSIS → Azure Data Factory
- SQL Server → cloud data warehouse
- SSRS / SSAS → Power BI
Without impact analysis:
- critical logic is lost,
- migrations take longer,
- business trust drops.
Impact analysis turns migration into a controlled, low-risk process.
Why Manual Impact Analysis Fails
Many teams attempt impact analysis using:
- spreadsheets,
- wiki pages,
- tribal knowledge,
- screenshots of ETL packages and reports.
This approach fails because it is:
- not scalable — dependencies change constantly,
- incomplete — column-level logic is usually missing,
- outdated — manual documentation ages quickly,
- expensive — engineers repeatedly answer the same questions.
True impact analysis requires automated lineage.
Data Lineage: The Foundation of Impact Analysis
Impact analysis is impossible without lineage.
Data lineage shows how data flows:
- from source database columns,
- through ETL transformations,
- into warehouse tables,
- through semantic models,
- and into BI reports.
There are two critical perspectives:
System-Level Lineage
Shows how platforms are connected.
Column-Level Lineage
Shows how individual fields move and transform.

This level of detail is what makes end-to-end impact analysis reliable.
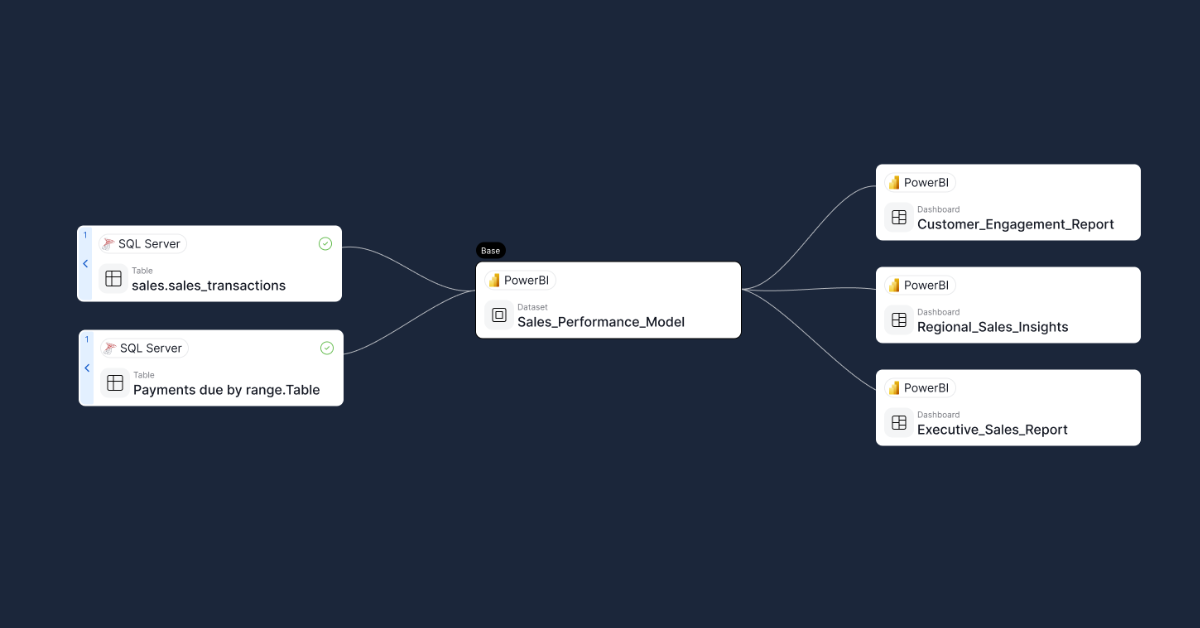
End-to-End Impact Analysis in Practice
Imagine this scenario:
The Profit column in the operational database will be recalculated and renamed.
With end-to-end lineage, you can immediately see:
- which ETL packages reference Profit,
- which transformations modify it,
- which warehouse tables store it,
- which BI datasets and measures use it,
- which reports expose it to business users.

Instead of guessing, teams can plan changes, notify owners, and test affected reports proactively.
How Dataedo Enables End-to-End Impact Analysis
Dataedo enables impact analysis by automatically connecting metadata across the entire analytics stack.
1. Automated Metadata Collection
Dataedo scans and imports metadata from:
- databases (SQL Server, PostgreSQL),
- ETL tools (SSIS),
- BI platforms (Power BI, SSAS, SSRS).
No manual dependency mapping.
2. End-to-End Lineage Across Systems
End-to-end lineage connects technical metadata across platforms into a single, navigable graph.
Instead of analyzing dependencies system by system, teams can follow a data element across databases, ETL pipelines, warehouses, and BI models in one view.

3. Impact Analysis with Governance Context
Impact analysis becomes truly actionable when technical lineage is enriched with business domains, glossary terms, and data quality signals.
Consider the following example visible in the screenshot:
Your organization has a documented Business Domain: HR in Dataedo.
The HR domain includes:
- a clear business description explaining how HR data supports recruitment, employment, and organizational reporting,
- linked business glossary terms such as Department, Employee, and Job Candidate,
- tables from multiple databases (recruitment system, core HR system, data warehouse),
- documented columns with business meaning and ownership,
- data quality ratios summarizing the overall health of HR data

Now imagine a change request:
A column related to employee department assignment is modified in the operational HR database.
With governance-aware impact analysis, teams can immediately see:
- that the column belongs to the HR business domain,
- that it is linked to the Department and Employee business terms,
- which tables across different databases store or derive department information,
- which downstream ETL processes and BI reports rely on department-based logic (e.g. headcount by department),
- the current data quality ratio for the HR domain, indicating whether department or employee data already has completeness or consistency issues.
This context fundamentally changes how the change is evaluated.
Instead of asking only:
“Which ETL jobs or reports will break?”
Teams can also ask:
- Will this change affect HR KPIs such as headcount, attrition, or open positions?
- Does it impact both Employees and Job Candidates, or only active employees?
- Is the data quality already below acceptable thresholds for this domain?
- Do HR stakeholders need to validate results after deployment?
Why This Matters for End-to-End Impact Analysis
By combining:
- lineage from databases through ETL to BI,
- business glossary terms like Department, Employee, and Job Candidate,
- ownership and stewardship,
- data quality ratios at the domain level,
impact analysis becomes business-aware, not just technical.
Teams can:
- prioritize changes affecting critical HR metrics,
- avoid cascading errors across recruitment and employee reporting,
- make informed decisions about risk and validation effort,
- protect trust in analytics used by HR leadership.
Impact analysis enriched with business meaning and data quality context ensures that changes are assessed not only for what they break, but for what they mean to the business.
Make Changes Without Breaking Trust
Analytics environments evolve constantly.
The difference between fragile analytics and trusted analytics is knowing how changes propagate across the entire data flow — before they happen.
End-to-end impact analysis, powered by automated lineage and metadata, makes that possible.
##See how Dataedo enables impact analysis from databases through ETL to BI
Book a demo or start a free trial to understand what will break — before it does.