Bart Gawrych
Bart Gawrych
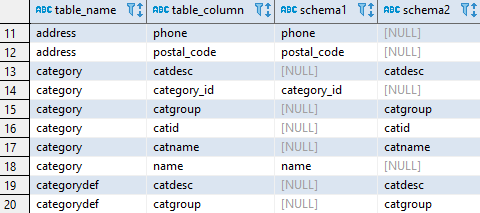
Query below compares columns (names) in tables between two Redshift schemas. It shows columns missing in either of two schema.
Query
select COALESCE(c1.table_name, c2.table_name) as table_name,
COALESCE(c1.column_name, c2.column_name) as table_column,
c1.column_name as schema1,
c2.column_name as schema2
from
(select table_name,
column_name
from information_schema.columns c
where c.table_schema = 'schema_1') c1
full join
(select table_name,
column_name
from information_schema.columns c
where c.table_schema = 'schema_2') c2
on c1.table_name = c2.table_name and c1.column_name = c2.column_name
where c1.column_name is null
or c2.column_name is null
order by table_name,
table_column;
Instruction
Replace schema_1 and schema_2 with names of two of your schemas (on Amazon Redshift instance) that you'd like to compare.
Columns
- table_name - name of the table
- table_column - name of column
- schema1 - if column exists in a table in schema 1 then column contains its name (repeats it from column column)
- schema2 - if column exists in a table in schema 2 then column contains its name (repeats it from column column)
Rows
- One row represents one distinct name of column in specific table. Row represents column if it exist only in one schema.
- Scope of rows: all distinct schema, table and column names in both databases.
- Ordered by table name and column name
Sample results