Databricks is a data processing cloud-based platform. It simplifies collaboration of data analysts, data engineers, and data scientists. Databricks is available in Microsoft Azure, Amazon Web Services, and Google Cloud Platform.
Databricks stores metadata in Apache Hive Metastore. By default, it uses an Internal Apache Hive Metastore hosted internally by cloud provied which cannot be accessed from third-pary application. However, it is also possible to connect Databricks to External Hive Metastore, created and hosted in an external database that can be accessed by a user. Such Metastore can be shared with other services such as Apache Impala or Spark Pool in Azure Synapse Analytics.
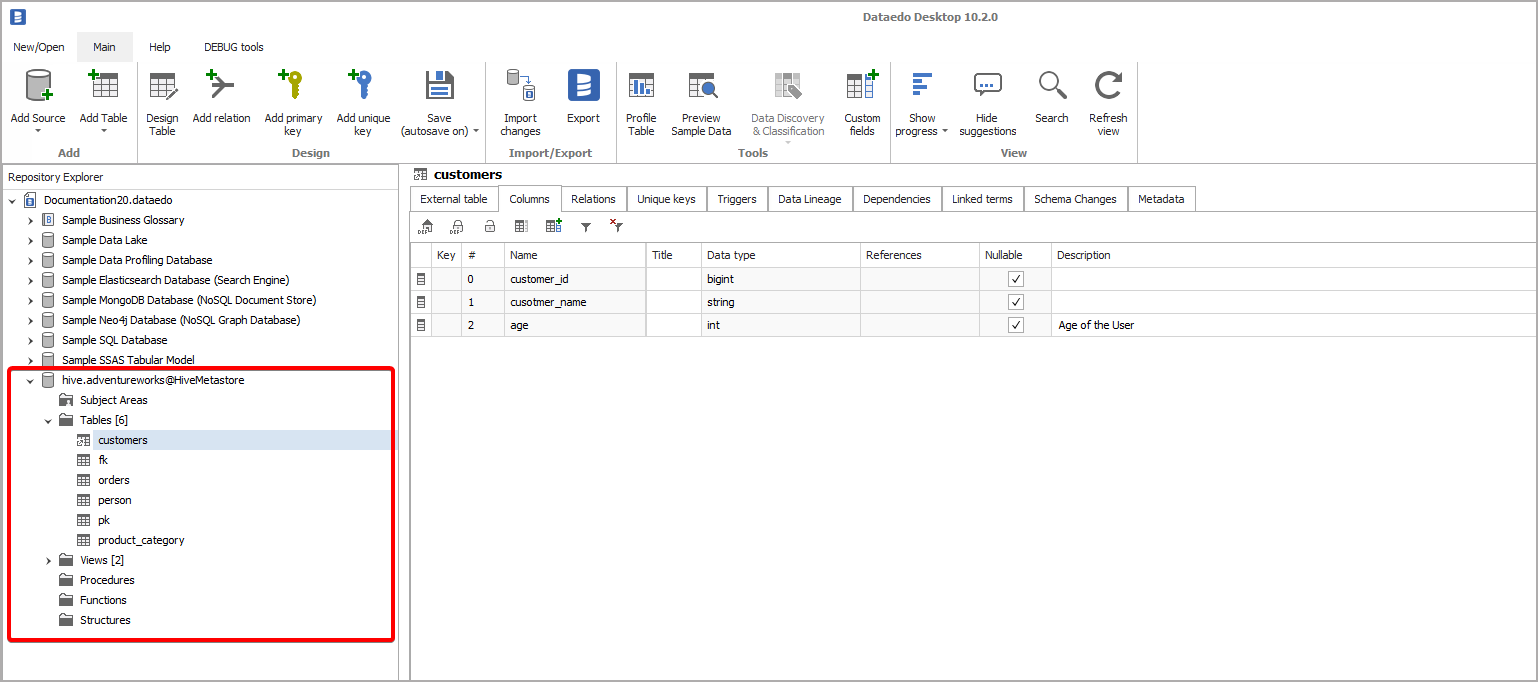
Dataedo provides a native connector to an Apache Hive Metastore which can be used to document metadata in Databricks.
Connector
Supported Versions
Hive Metastore 3.x
Supported Metadata
- Tables
- Table type:
- Managed Table
- Index Table
- External Table
- Columns:
- Data type
- Nullable
- Default value
- Check constraint
- Unqiue constraint
- Primary keys
- Columns
- Foreign keys
- Columns
- Relations
- Table type:
- Views
- View type:
- Materialized view
- Virtual view
- Columns (see Tables)
- View type:
Data profiling
Datedo does not support data profiling in Databricks.
Connect to Databricks with External Hive Metastore
Get connection details
Log into your Databricks account and open the Compute page. Then go to Spark config tab and find the connection details:
- javax.jdo.option.ConnectionURL
- javax.jdo.option.ConnectionUserName
- javax.jdo.option.ConnectionPassword
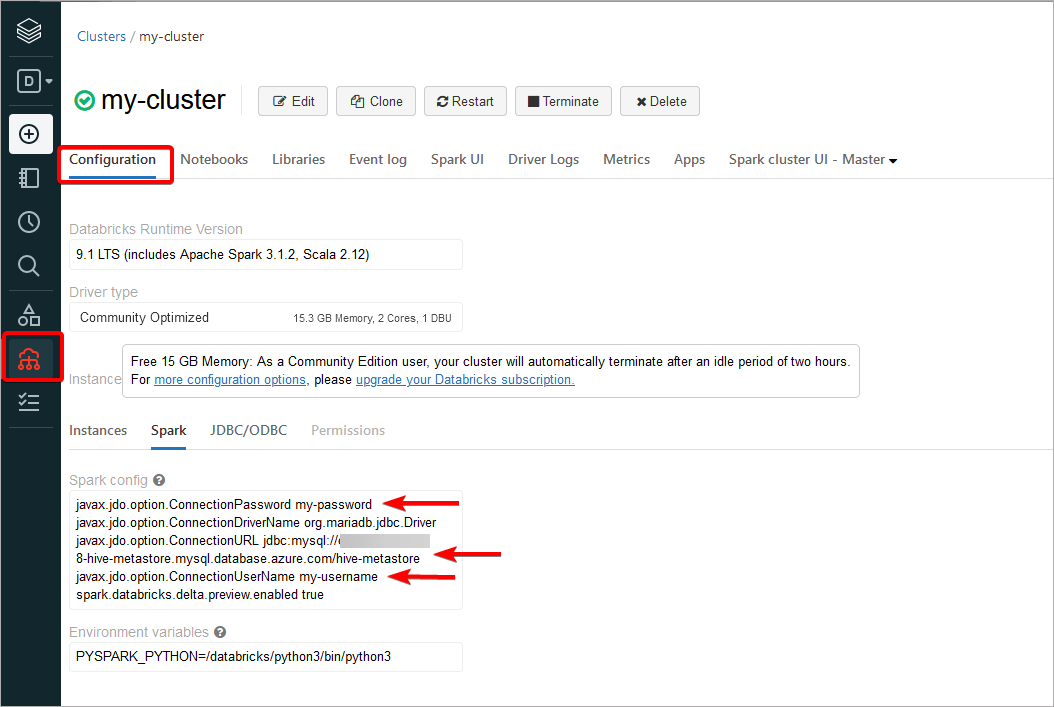
Once you have all the properties, you need to extract details:
- javax.jdo.option.ConnectionUserName - Dataedo username.
- javax.jdo.option.ConnectionPassword - Dataedo password.
- javax.jdo.option.ConnectionURL - here you need to extract infromation from jdbc connection string which has format: jdbc:[database_engine]://[database_address]:[database_port]/[metastore_database]?others_options. Previous example of configuration uses MySQL jdbc connector, although others database engines follow convention.
If you cannot find mentioned properties in Spark config window, but there is a property named hive.metastore.uris:
hive.metastore.uris thrift://<metastore-host>:<metastore-port>
You need to connect to the metastore-host and follow the instruction for Apache Hive Metastore
In case if none of the mentioned properties are available, your Databricks instance uses Internal Apache Hive Metastore and as such cannot be documented with Databricks (with external Hive Metastore) connector.
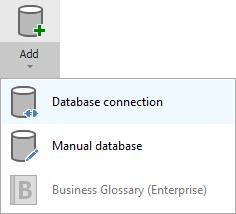
Add new connection
To connect to Hive Metastore and create new documentation by clicking Add documentation and choosing Database connection.
On the connection screen choose Databricks (with external Hive Metastore) as DBMS.
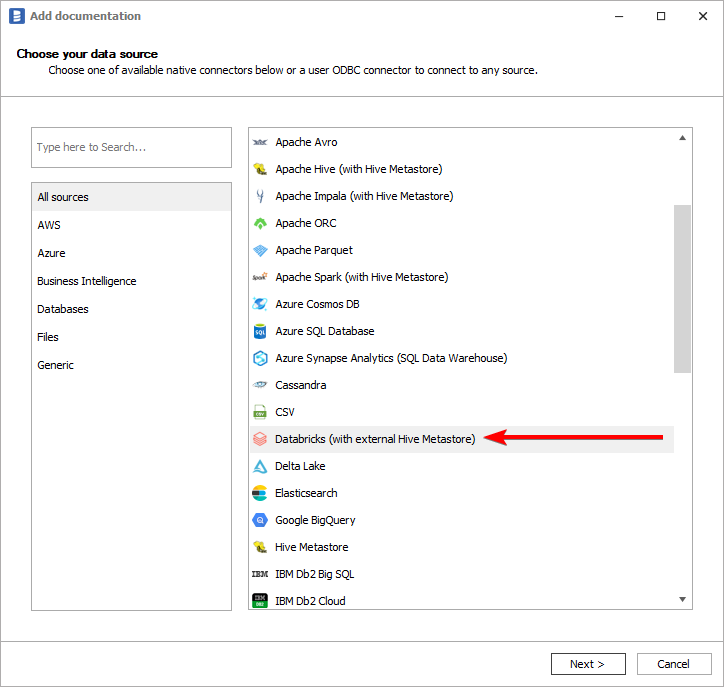
You need to select database engine hosting Hive Metastore:
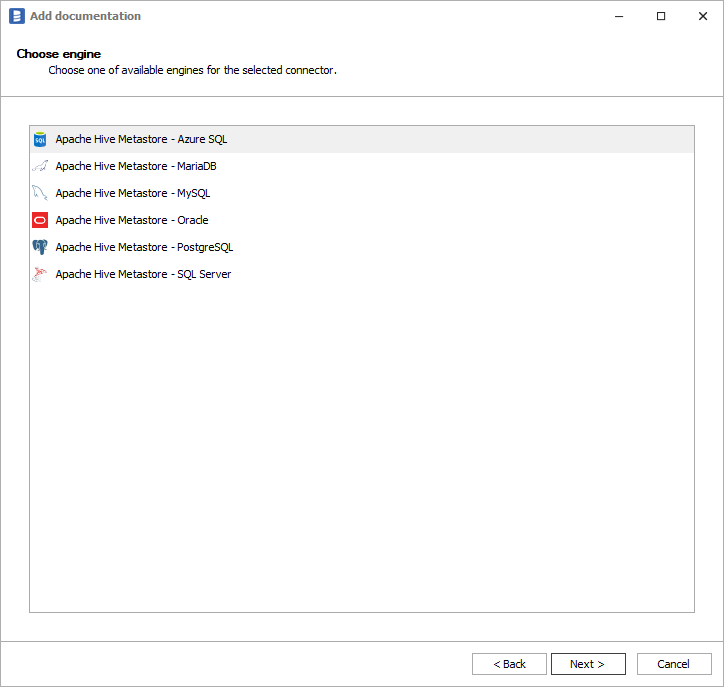
Connection details
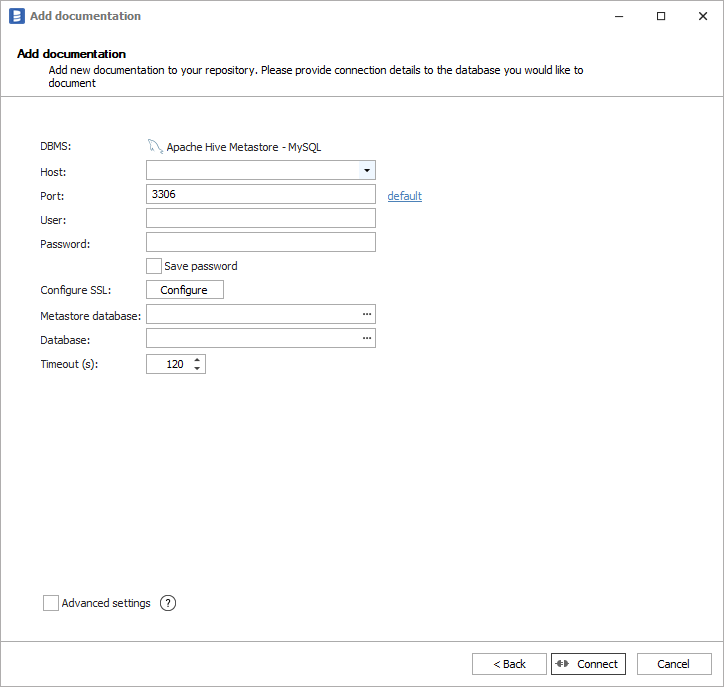
Then you need to provide connection details accordingly for selected database:
Following connection example will be based on MySQL, although others databases will have similar fields required for connection:
- Host - hostname or IP address of server on which database is available,
- Port - port under which database is available,
- User - username,
- Password - password,
- Metastore database - name of MySQL database hosting the metastore. You can expand list of databases by clicking ... button.
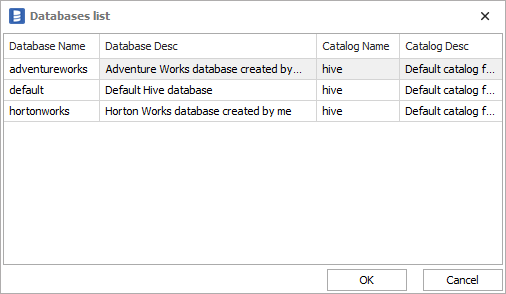
- Database - name of Hive database. You can expand list of databases by clicking ... button. You will get a table of Hive databases with Database Name, Description, Catalog Name and Catalog description columns:
Obtaining all details is described in chapter How to get connection details of Hive Metastore database.
Importing metadata
When connection was successful Dataedo will read objects and show a list of objects found. You can choose which objects to import. You can also use advanced filter to narrow down list of objects.
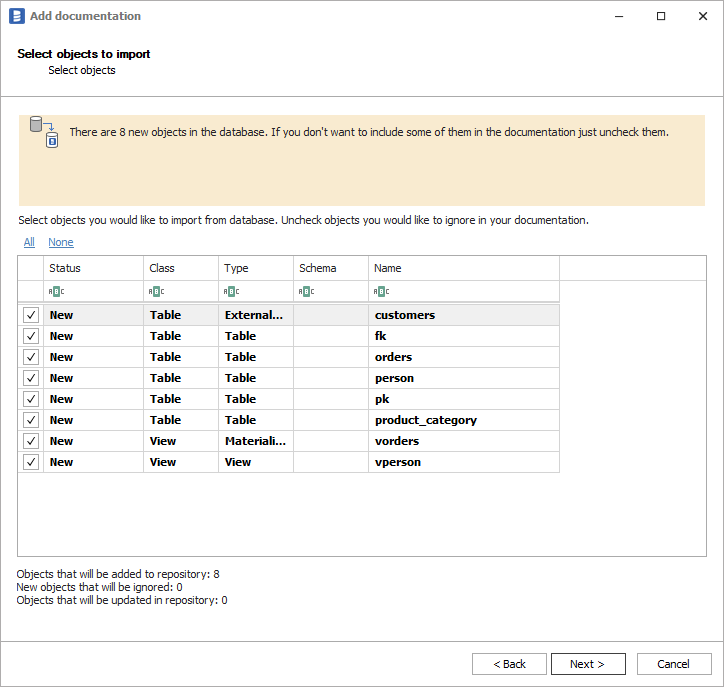
Confirm list of objects to import by clicking Next.
Next screen allow you to change default name of the documentation under which it will be visible in Dataedo repository.
Click Import to start the import. Once import is done, close import window with Finish button.
Outcome
Your database has been imported to new documentation in the repository.