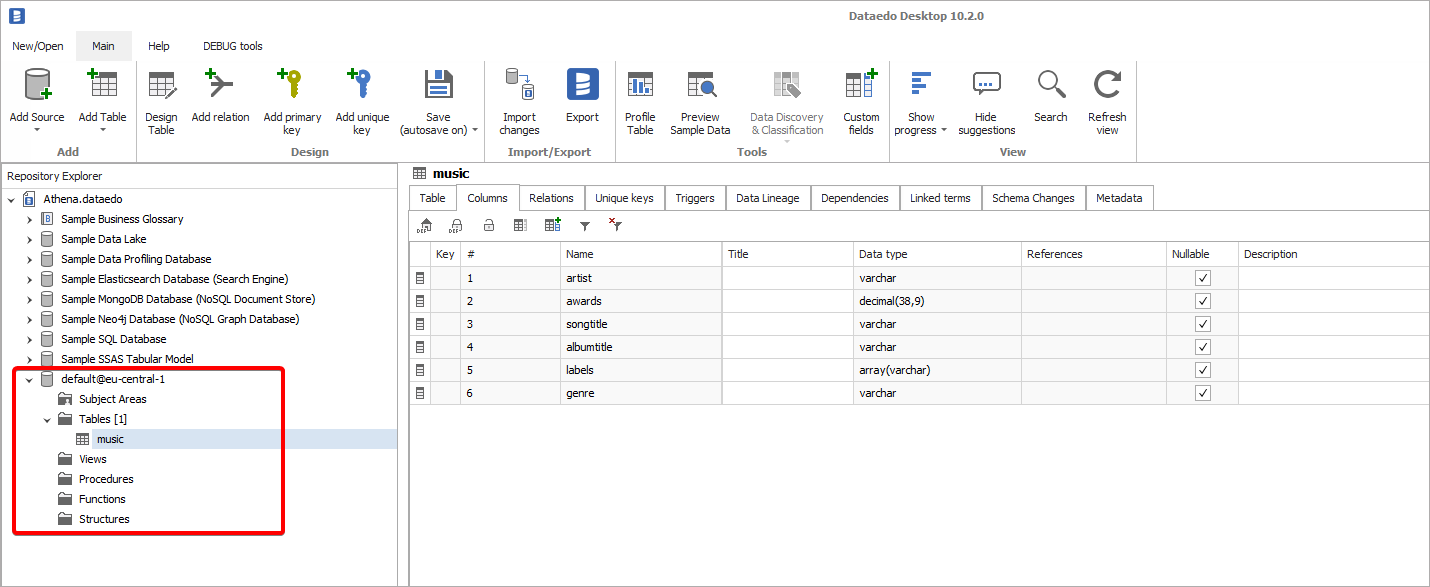
Dataedo supports connector for Amazon Athena, a query engine that allows querying various data sources on Amazon Web Services. It allows access to AWS Glue Data Catalog that can catalog files in S3, tables DynamoDB, DocumentDB, RDS databases and Redshift.

This article explains how to catalog files in AWS S3 in Dataedo using Amazon Athena connector. Please check alternative method of cataloging files from s3 in Dataedo.
Set up AWS Services
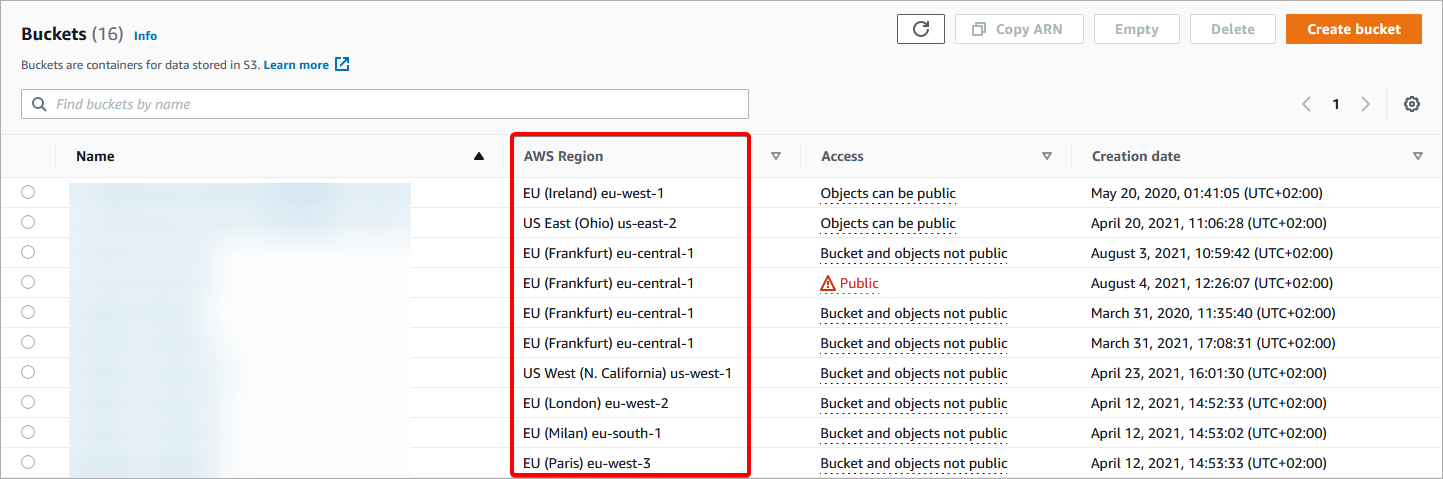
Get S3 Bucket AWS Region
All services configured later need to be created in the same region as S3 Bucket. To get the region of S3 Bucket, log in to AWS Console, find the S3 service, and open it. Then find the region name in list of your buckets.
Create S3 buckets
To use the Amazon Athena you need a S3 bucket to store the query results.
Important: Bucket need to be in the same region as the S3 bucket which will be documented.
Following is a brief instruction on how to create an S3 bucket (see more at AWS documentation) NOTE: you can use an existing bucket:
- Search for S3 service.
- Click the Create bucket button.
- Set the Bucket name and AWS region (same as AWS S3 bucket region!).
- Other options can be left as default.
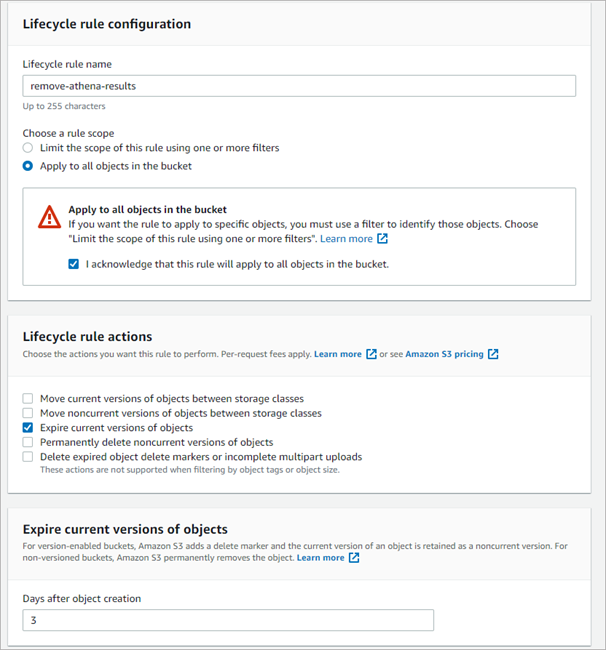
(Optional) Once the bucket is created, set the Lifecycle configuration. You can do this by:
- Clicking the name of the bucket,
- Opening Management tab,
- Clicking Create lifecycle rule,
- Configuring Lifecycle rule. We use the following configuration, which expires object after 3 days:
Set up AWS Athena
You do not need to explicitly activate Athena as by default it is enabled. Although, if you have never used it in a selected region, you need to select an S3 bucket for storing query results.
To configure this service for the first time, find Athena Service in an AWS console. If it is the first launch in a region, you will see an Athena home screen. Click the Explore the query editor button, open settings tab and click the Manage button.

Open a list of available buckets by clicking Browse S3 and select bucket in which query results will be saved. IMPORTANT: If you cannot find a bucket, make sure it was created in the same region as currently selected Save settings.
Create an IAM user
Dataedo connects to AWS Athena with an IAM user, which is a default authentication method for programmatic access. Account for Dataedo will require the following permissions:
- AWSQuicksightAthenaAccess – to read metadata with Athena
- AmazonS3FullAccess – to save query results in an S3 bucket
- AWSLambdaRole – to run the Lambda function
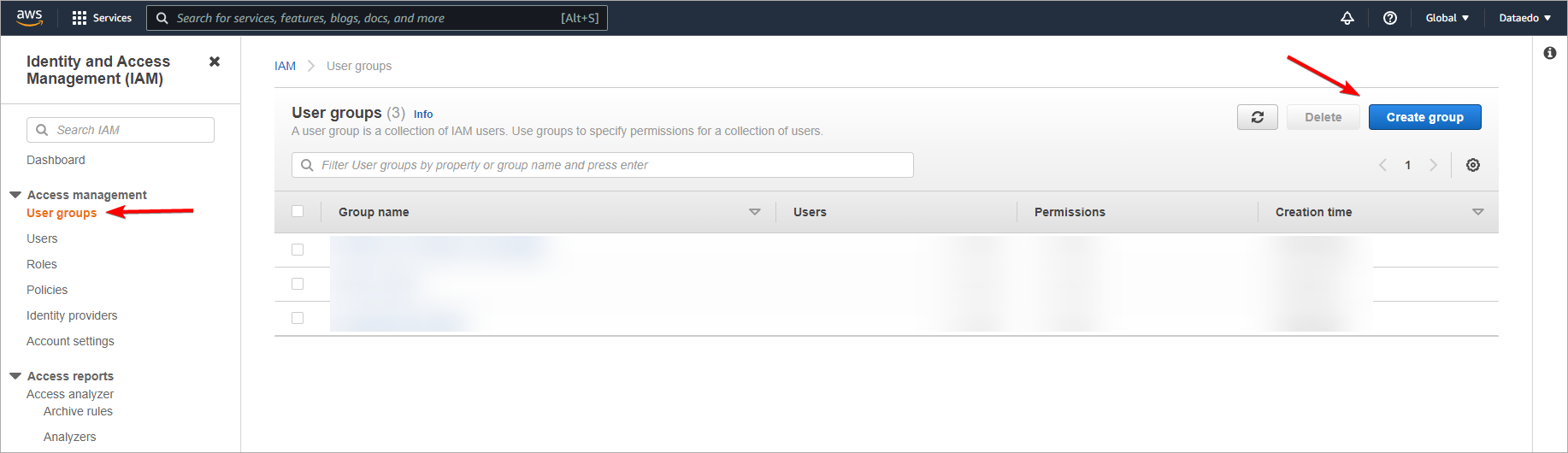
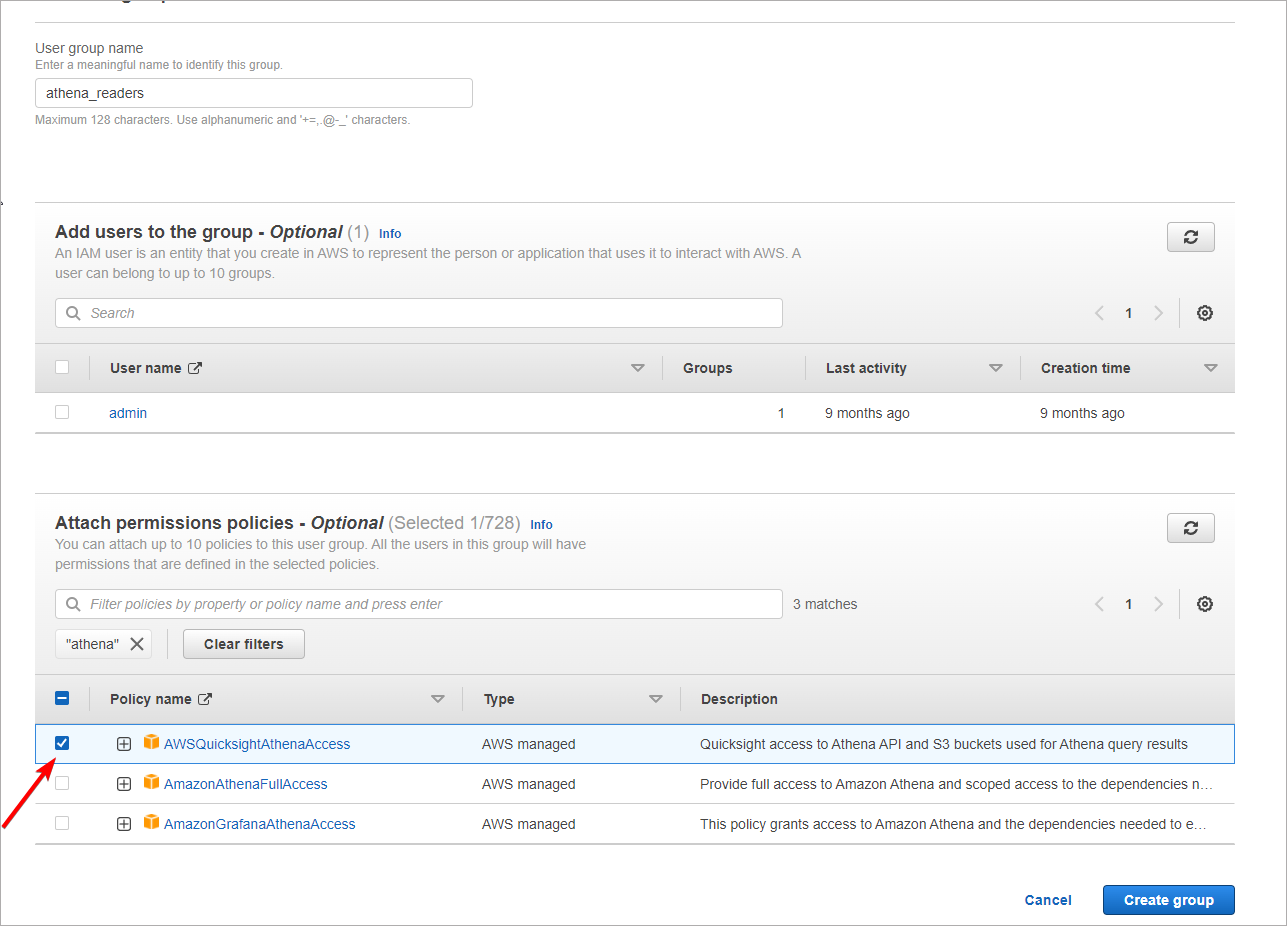
First, create an IAM group with the required permission. Find IAM Service in AWS console, open the User Groups tab, and click Create Group button.
Give your group a distinctive name, and add the aforementioned permissions in Attach permissions policies section.
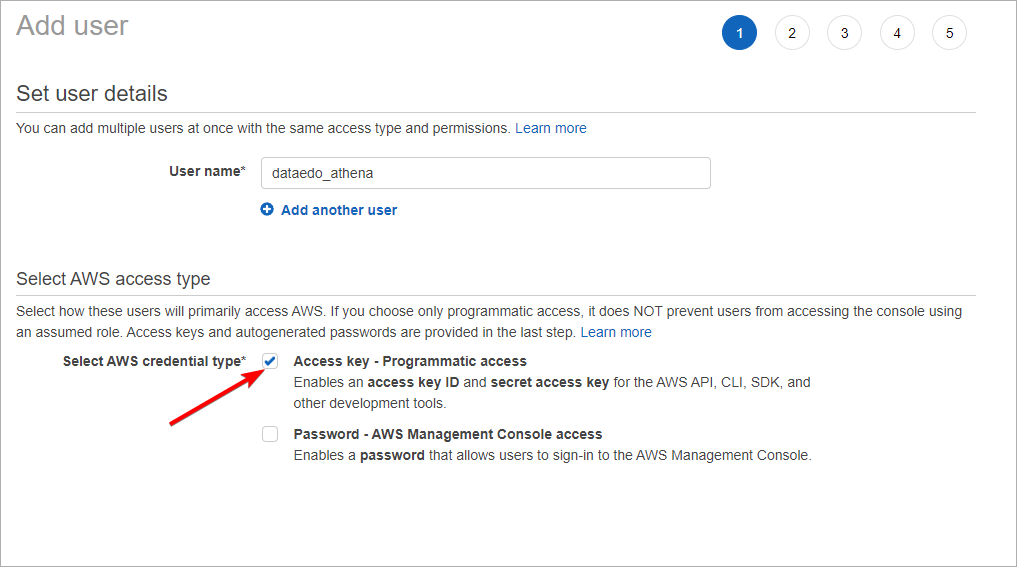
Go back to IAM service main window and open the Users tab and click the Add user button. Give a user a name and select Access Key – Programmatic access in the Select AWS access type section.
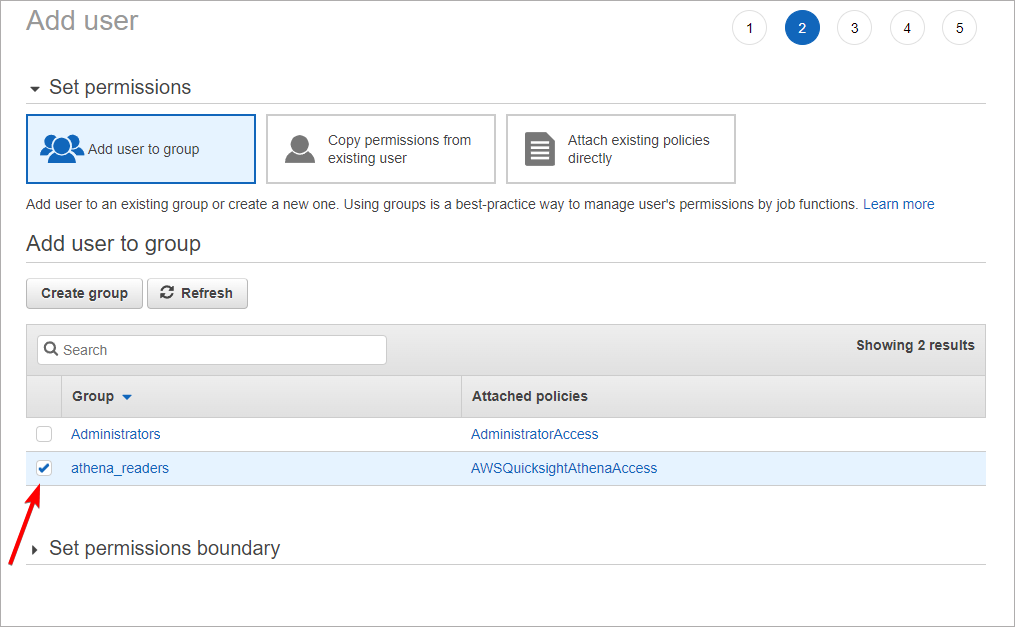
Go next and add the user to the group created in the previous step. Other options can be left default.
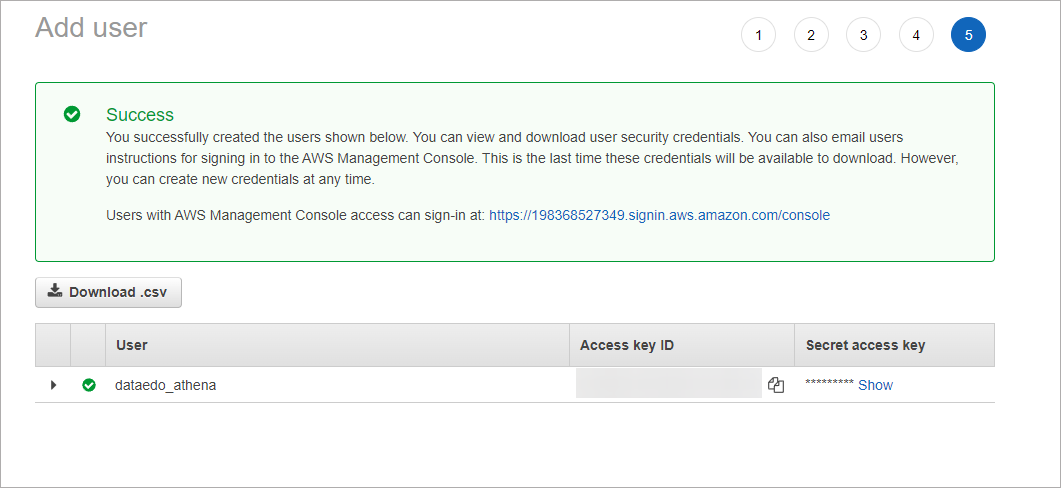
In the last step, AWS will provide you with an Access key ID and Secret access key. These are credentials to your IAM account which you will later use to connect to Athena with Dataedo. Store them safely (we recommend saving these values in an encrypted password manager file).
Catalog files in AWS Glue Data Catalog
To document files in S3 with Athena you need to catalog them first with AWS Glue Data Catalog.
Create a AWS Glue Crawler for S3
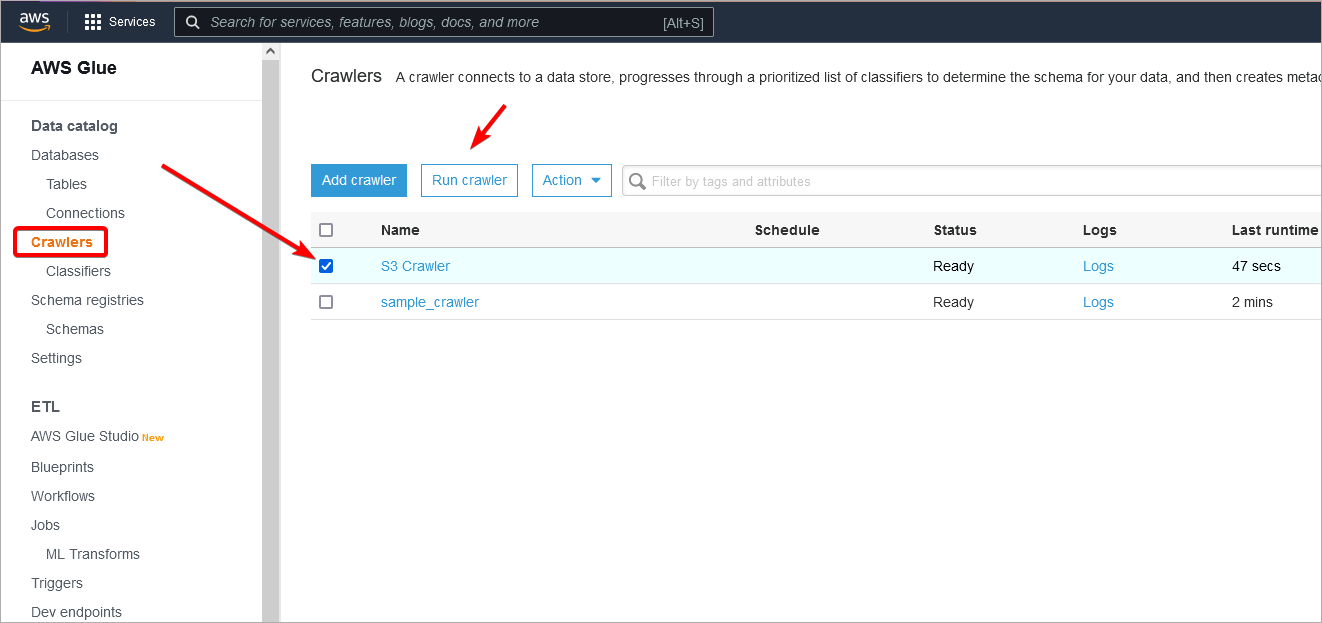
Open AWS Glue Service in AWS Console. Then select tab Crawlers. It will open Crawlers page:
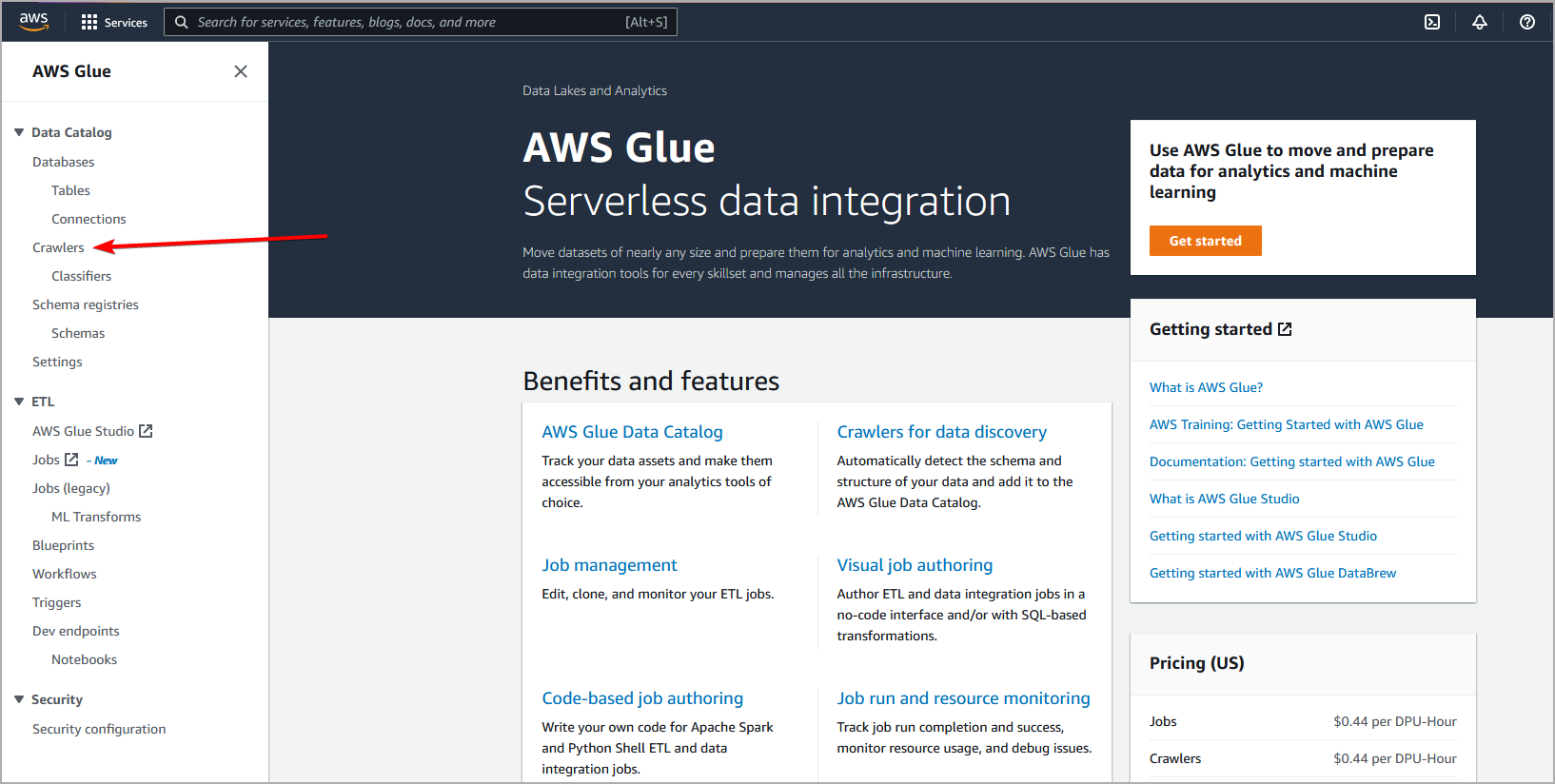
Then on Crawlers page click Add Crawler button. Keep in mind that AWS Glue Crawler must be defined in same region as bucket you want to crawle (you can change region in upper right corner) :
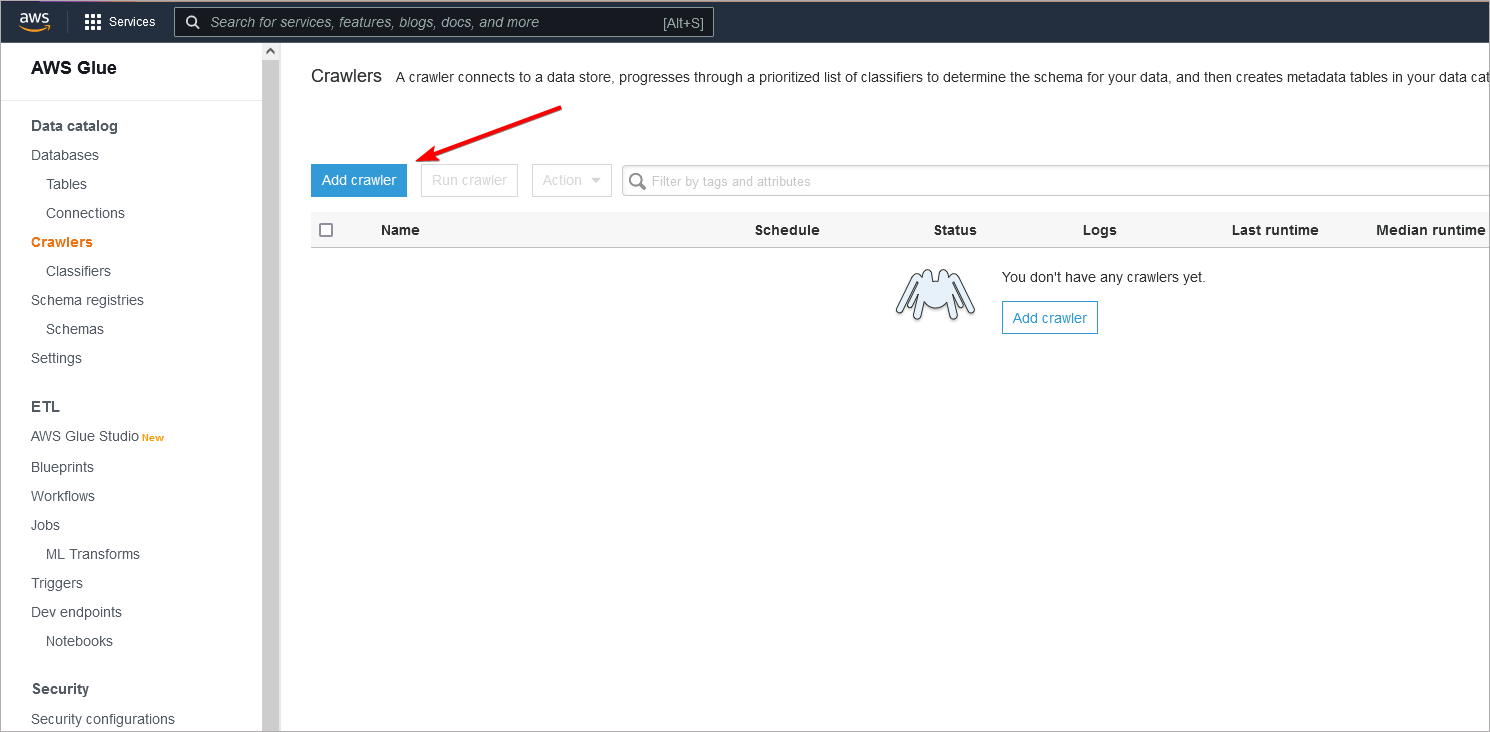
Then you need to go through several steps to create a crawler:
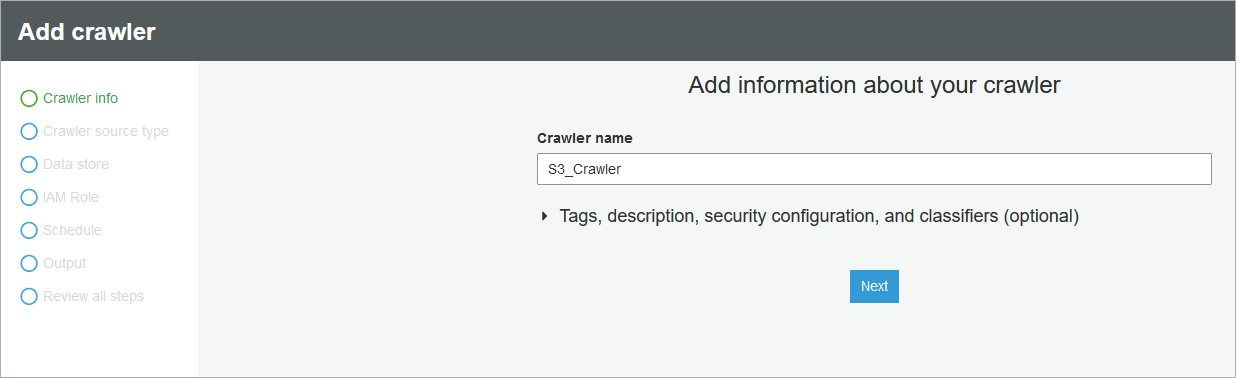
- Add basic information - here you need to provide crawler name and some optional information like Tags, Description etc.
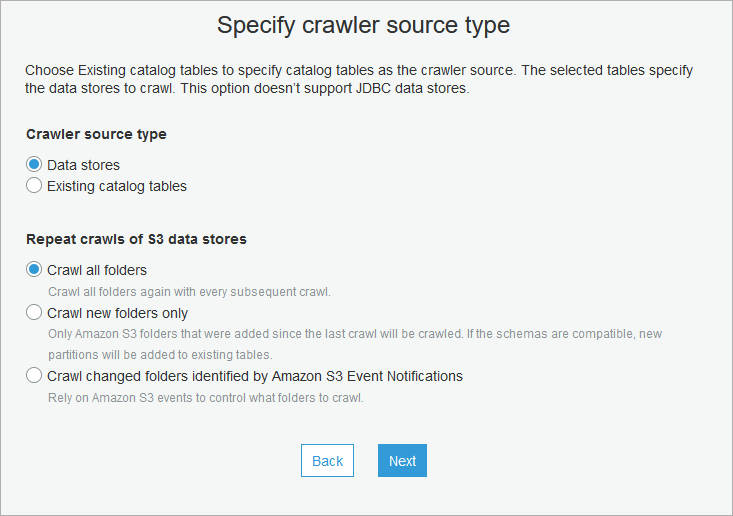
- Specify crawler source - in source type select Data Stores. In Repeat crawls..., we'll go with Crawl all folders, but you can select any option that fits best.
- Next you have to select objects that will be crawled. In Choose a data store select S3, and in Include path select whole bucket, catalog or even a file. Other options are not required:
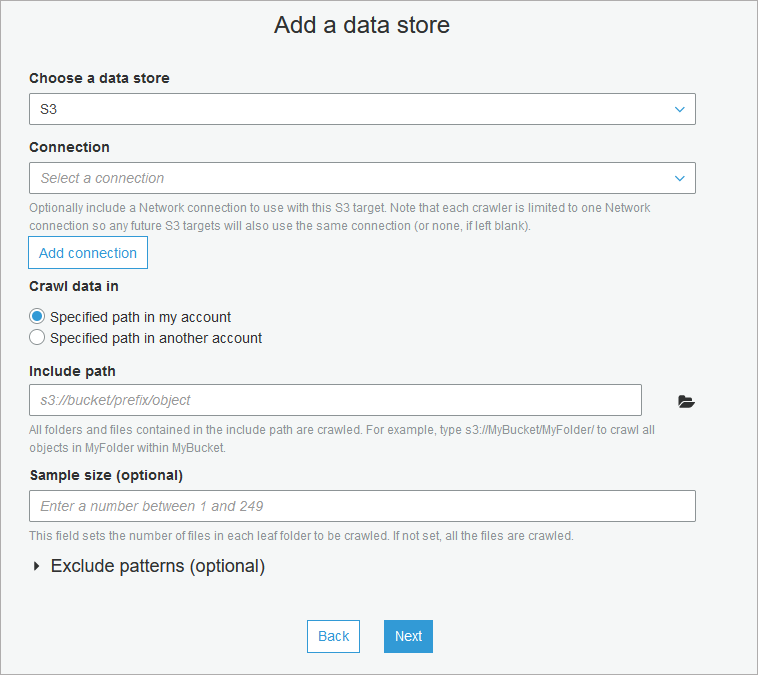
In next step you can add another data source by checking Yes for Add another data store or continue by checking No.
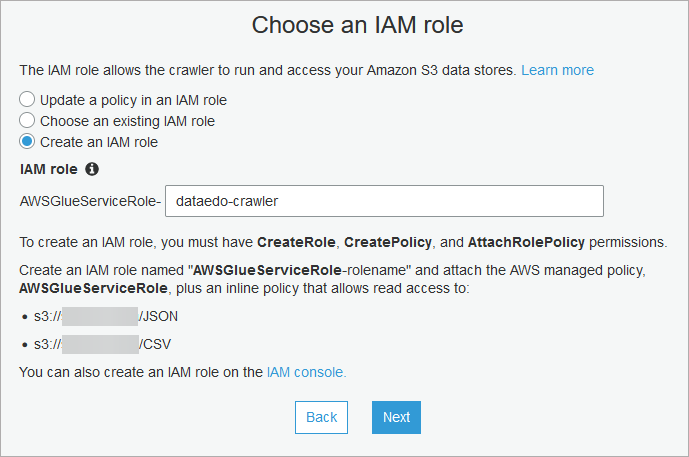
Next you need to Select IAM role to read from S3 bucket or simply create a new one by typing in name of role. Created role will have all required permissions.
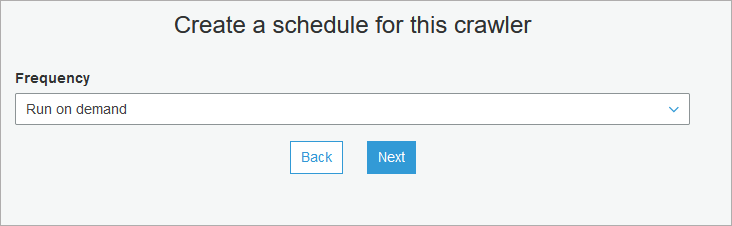
- In schedule select how frequent your crawler will read files. We'll select Run on demand as we need to run this crawler only before updating documentation in Dataedo.
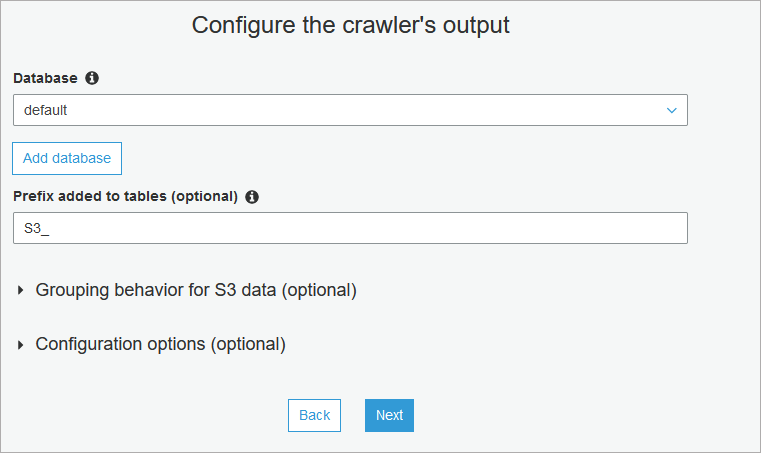
- Select to which Athena database metadata will be saved and optionally add prefix to crawled tables. Also, review additional options.
- Review options and create a crawler by clicking Finish.
Run the crawler
Open Crawlers page and find crawler tha you created. Select it on the list and click Run Crawler button.
Connecting Dataedo to Amazon Athena
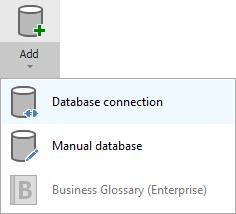
Add new connection
To connect to Athena create new documentation by clicking Add documentation and choosing Database connection.
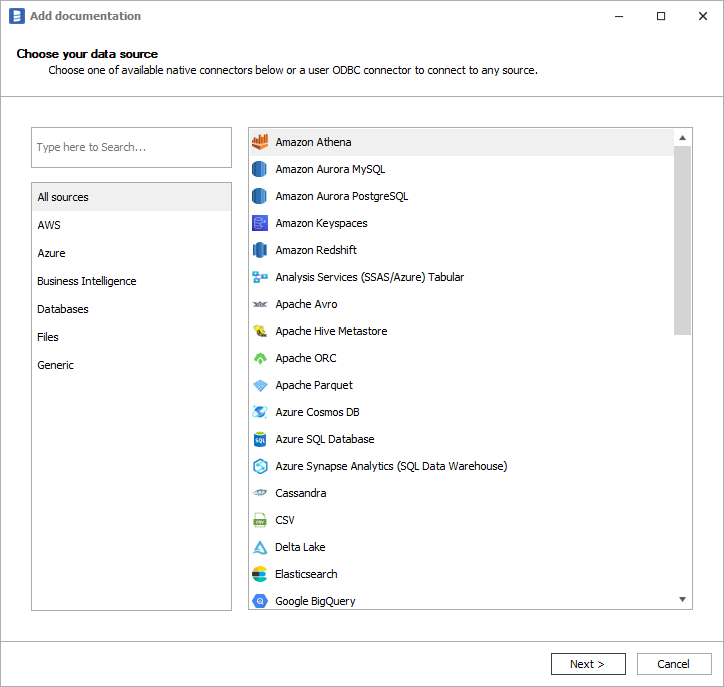
On the Add documentation window choose Amazon Athena:
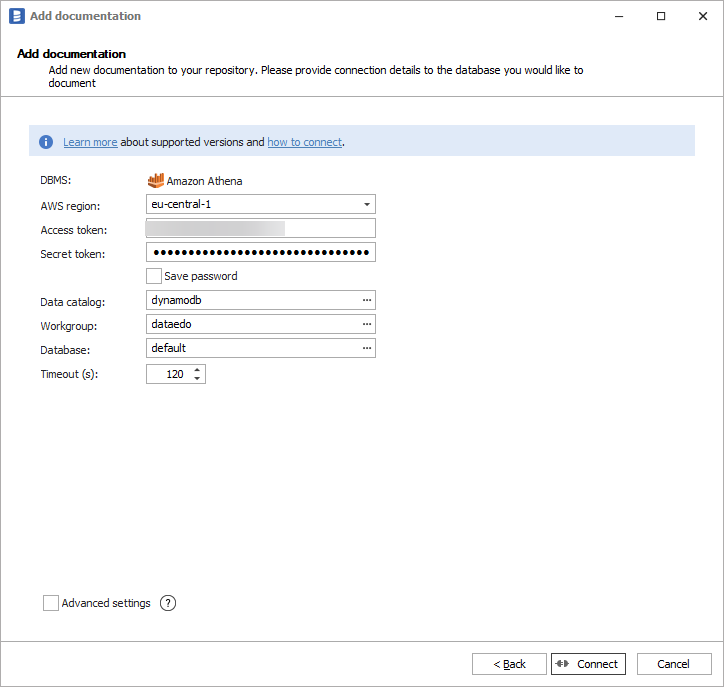
Connection details
Provide connection details:
- AWS Region - AWS region in which Athena and DynamoDB reside,
- Access Token - IAM user access key ID,
- Secret Token - IAM user secret key,
- Data Catalog - data catalog in which your S3 data resides
- Workgroup - Athena workgroup
- Database - Athena database.
Importing Metadata
When connection was successful Dataedo will read objects and show a list of objects found. You can choose which objects to import. You can also use advanced filter to narrow down list of objects.
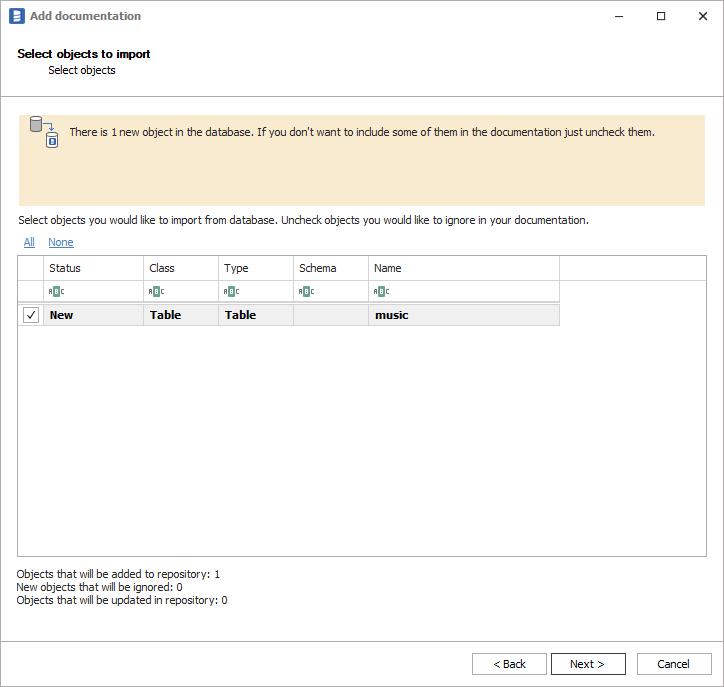
Confirm list of objects to import by clicking Next.
Next screen allow you to change name of the documentation under which it will be visible in Dataedo repository.
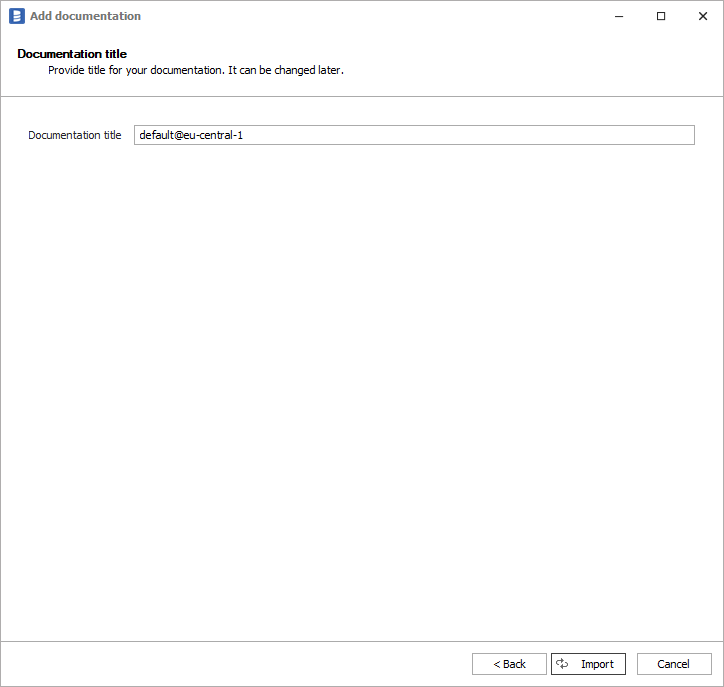
Click Import to start the import.
When done close import window with Finish button.
Outcome
Your S3 objects schemas have been imported to new documentation in the repository.