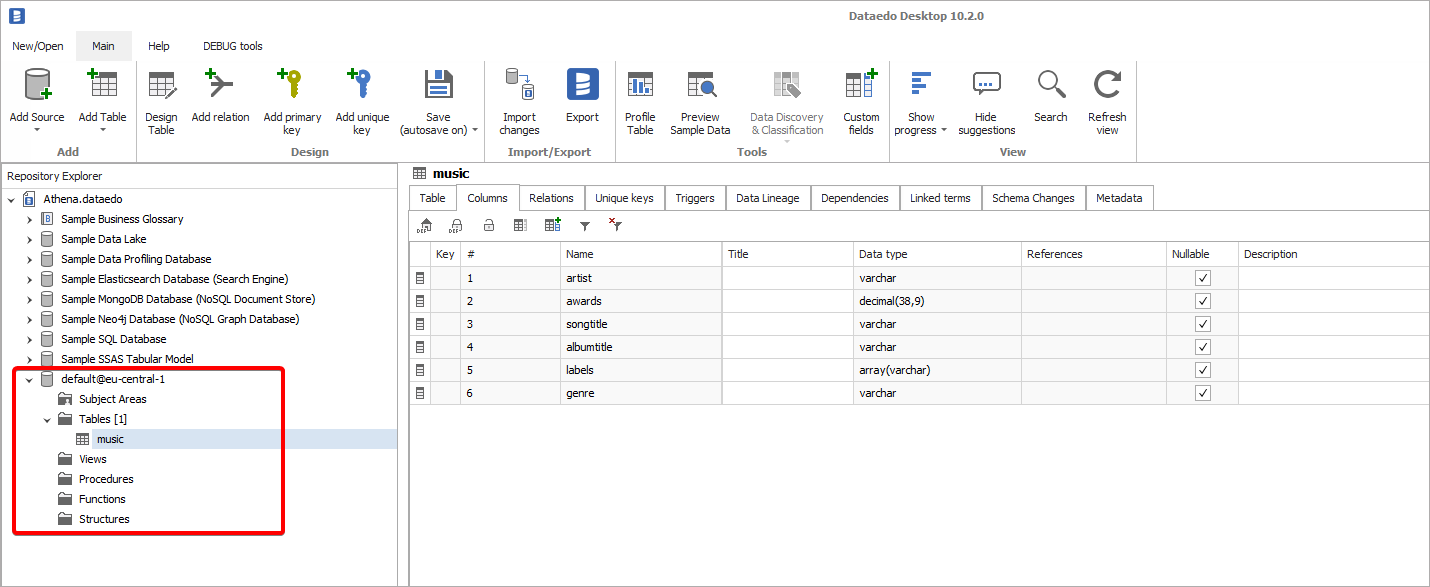
With the Athena connector you can also document your AWS Glue catalog data.

The following workflow diagram shows how AWS Glue crawlers interact with data stores and other elements to populate the Data Catalog.

The following is the simplified workflow for how a crawler populates the AWS Glue Data Catalog:
- A crawler runs cliassifiers to detect the format and schema of your data.
- Once one of the classifiers successfully recognize the structure of your data it creates a schema.
- Then the crawler connects to the data source.
- The schema is generated.
- The crawler writes metadata to the Data Catalog. A table definition contains metadata about the data in your data store. The table is written to a database, which is a container of tables in the Data Catalog.
- From now on you can query data through Glue Data Catalog using Athena.
All databases and tables defined in the AWS Glue catalog can be accessed through AWS Athena by choosing "AwsDataCatalog" as a data source.
Connector
Supported metadata and schema elements
- Tables
- Columns
- Data type
- Position
- Nullable
- Description
- Default value
Data profiling
Datedo does not support data profiling in AWS Glue Data Catalog.
Configure AWS Services
Create S3 buckets
To use Amazon Athena you need have set up a S3 Bucket for Athena query results. You can use existing buckets instead of creating new one.
Important: Buckets need to be in the same region as an Amazon Athena.
Following is a brief instruction on how to create an S3 bucket (see more at AWS documentation):
- Search for S3 service.
- Click the Create bucket button.
- Set the Bucket name and AWS region (same as DocumentDB region!).
- Other options can be left as default.
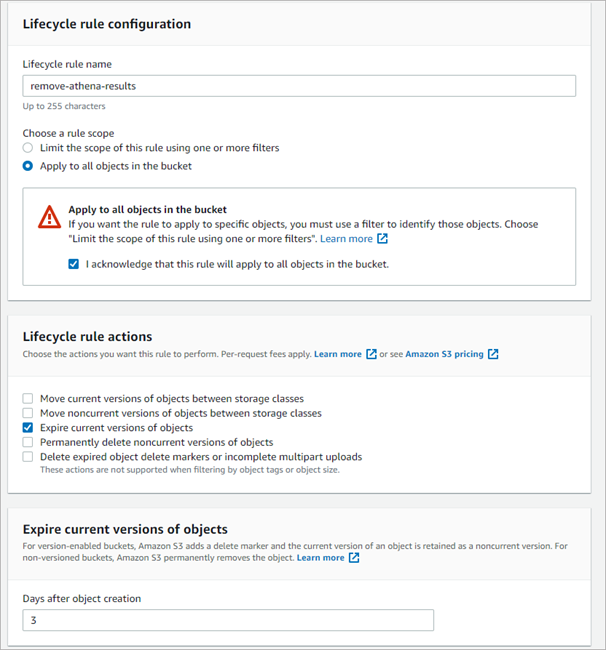
(Optional) Once the bucket is created, set the Lifecycle configuration. You can do this by:
- Clicking the name of the bucket,
- Opening Management tab,
- Clicking Create lifecycle rule,
- Configuring Lifecycle rule. We use the following configuration, which expires object after 3 days:
Set up AWS Athena
You do not need to explicitly activate Athena as by default it is enabled. Although, if you have never used it in a selected region, you need to select an S3 bucket for storing query results.
To configure this service for the first time, find Athena Service in an AWS console. If it is the first launch in a region, you will see an Athena home screen. Click the Explore the query editor button, open settings tab and click the Manage button.

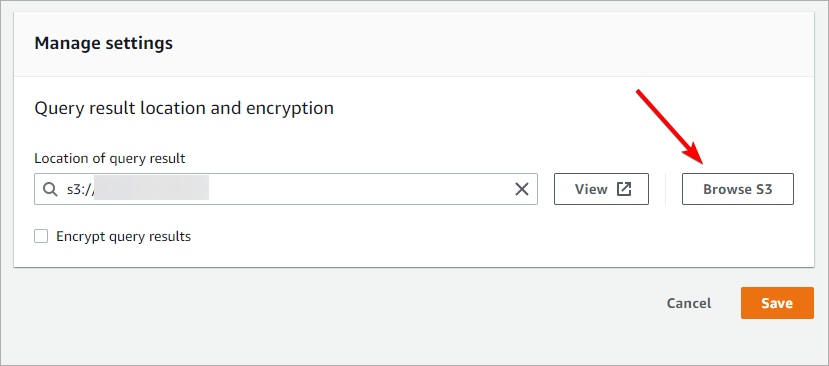
Open a list of available buckets by clicking Browse S3 and select bucket in which query results will be saved. IMPORTANT: If you cannot find a bucket, make sure it was created in the same region as currently selected Save settings.
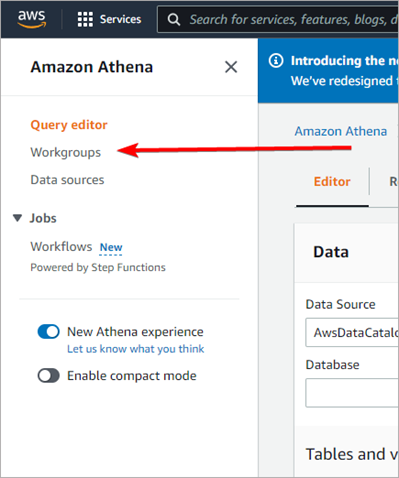
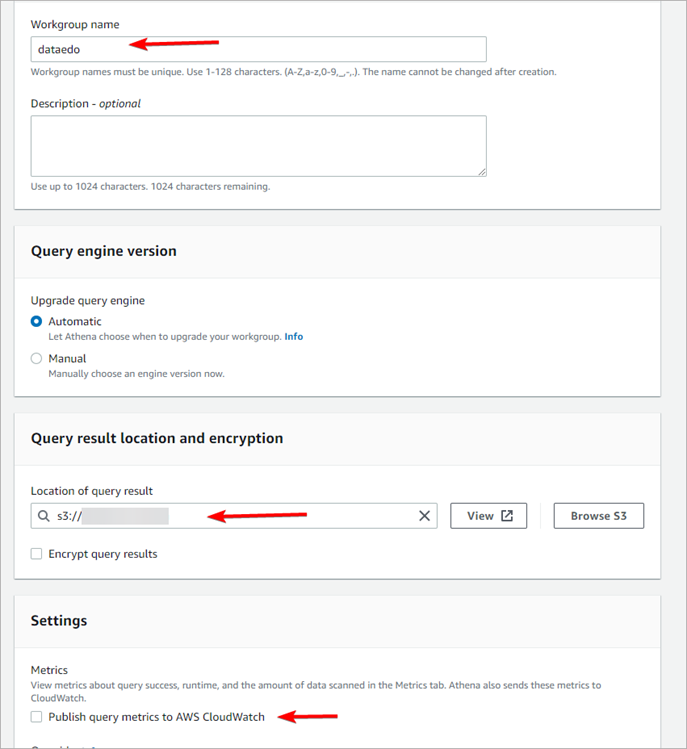
Now you need to configure a custom Workgroup to connect Athena to DocumentDB. Open the Workgroups tab and click the Create workgroup button.
Set the name for the workgroup and select the S3 bucket (can be the very same bucket as previously selected for Athena). Additionally, you can uncheck Publish query metrics to AWS CloudWatch.
Create an IAM user
Dataedo connects to AWS Athena with an IAM user, which is a default authentication method for programmatic access. Account for Dataedo will require the following permissions:
- AWSQuicksightAthenaAccess – to read metadata with Athena
- AmazonS3FullAccess – to save query results in an S3 bucket
- AWSLambdaRole – to run the Lambda function
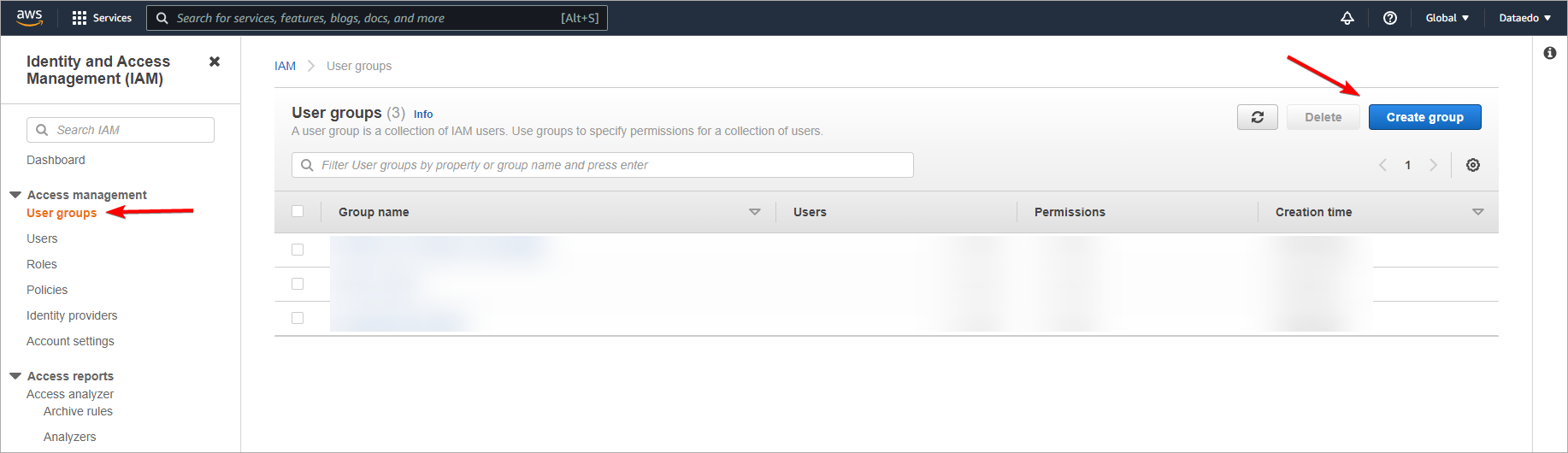
First, create an IAM group with the required permission. Find IAM Service in AWS console, open the User Groups tab, and click Create Group button.
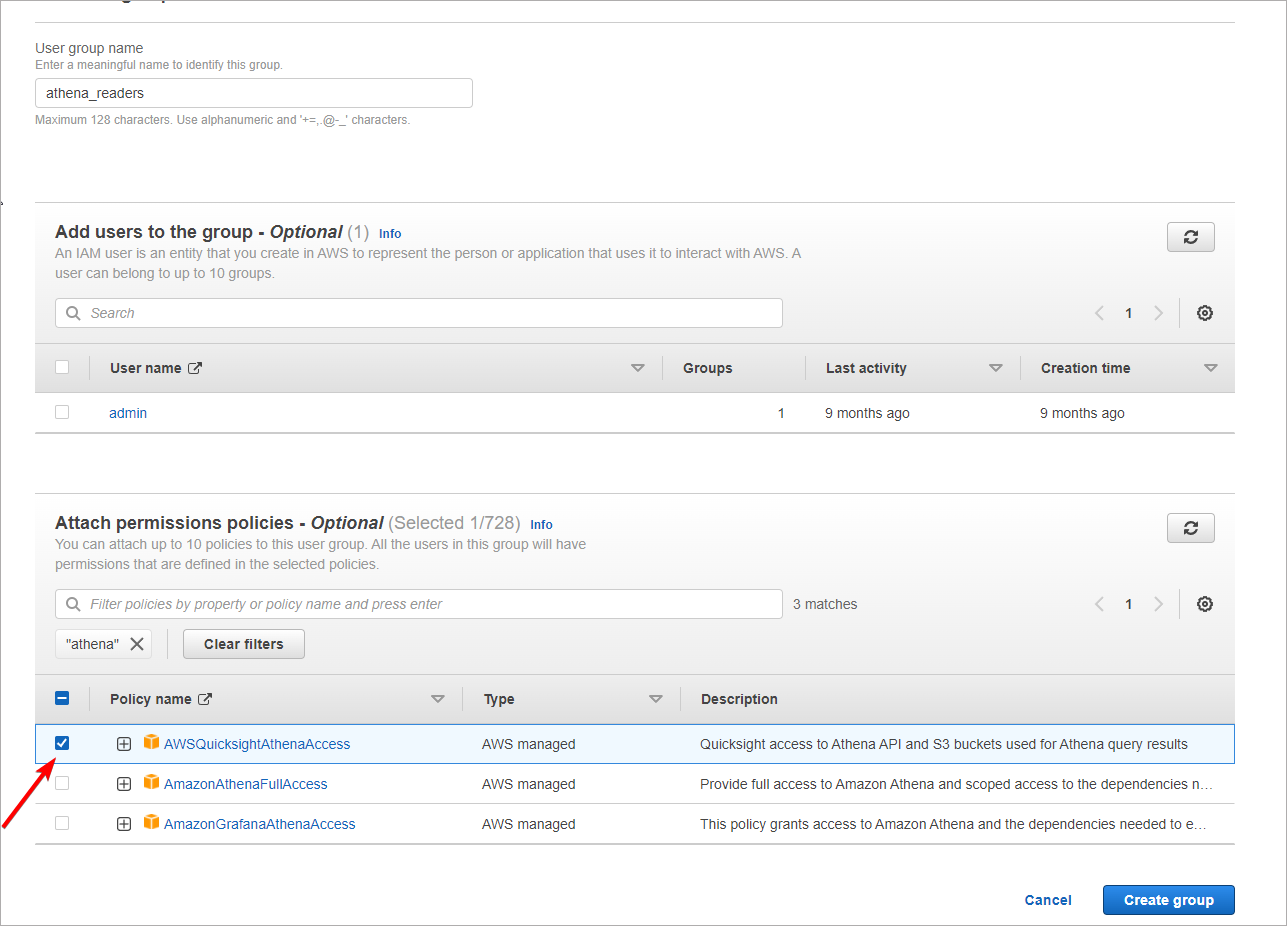
Give your group a distinctive name, and add the aforementioned permissions in Attach permissions policies section.
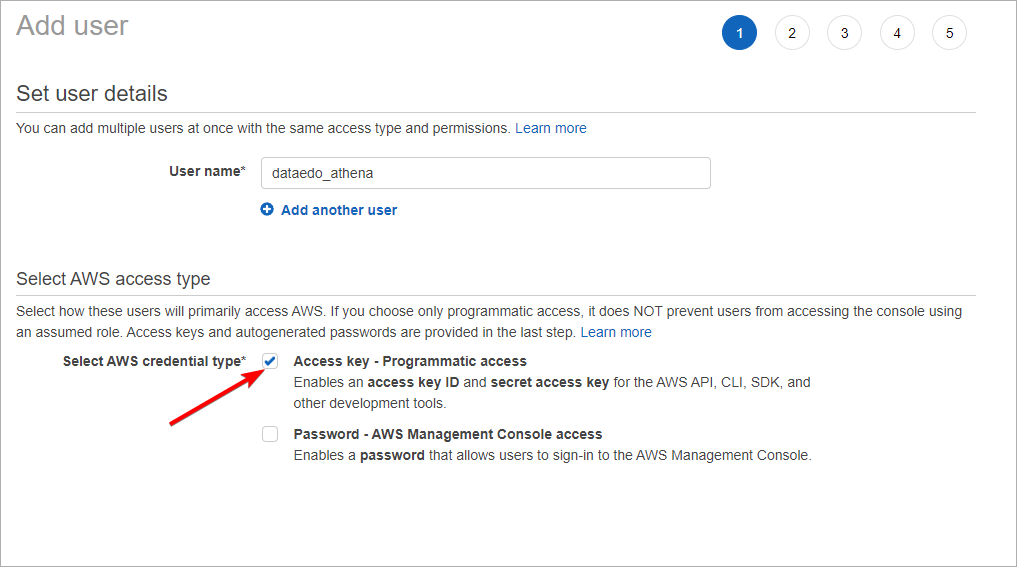
Go back to IAM service main window and open the Users tab and click the Add user button. Give a user a name and select Access Key – Programmatic access in the Select AWS access type section.
Go next and add the user to the group created in the previous step. Other options can be left default.
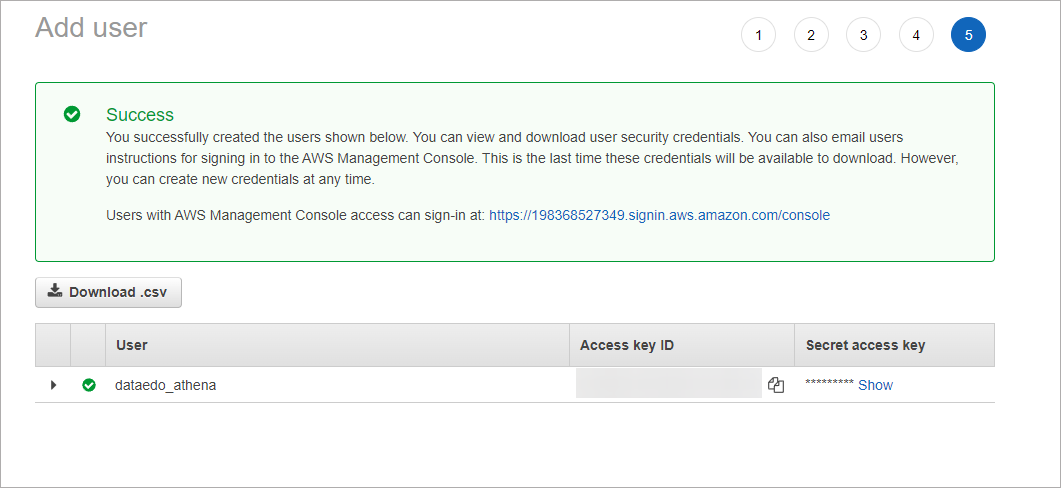
In the last step, AWS will provide you with an Access key ID and Secret access key. These are credentials to your IAM account which you will later use to connect to Athena with Dataedo. Store them safely (we recommend saving these values in an encrypted password manager file).
Connect Dataedo to Amazon Glue Data Catalog with AWS Athena
Add new connection
To connect to Amazon DocumentDB with Athena create new documentation by clicking Add documentation and choosing Database connection.
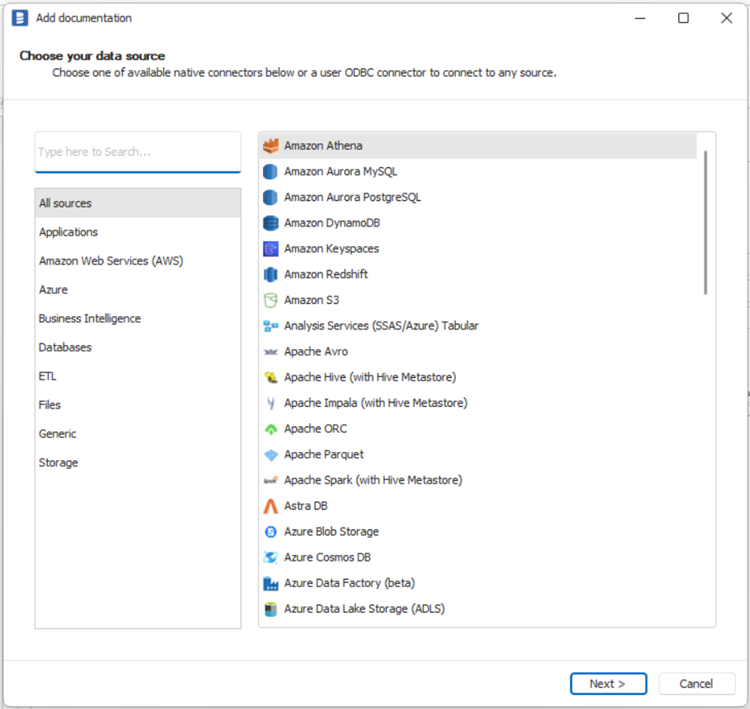
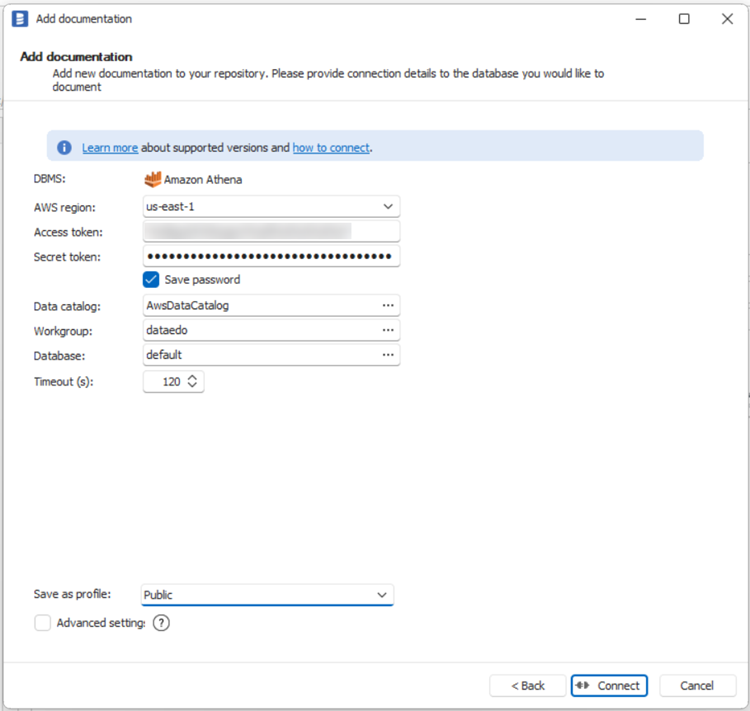
On the Add documentation window choose Amazon Athena:
Connection details
Provide connection details:
- AWS Region - AWS region in which Athena reside,
- Access Token - IAM user access key ID,
- Secret Token - IAM user secret key,
- Data Catalog - as a data catlog provide the name of your Aws Glue Data Catalog - AwsDataCatalog
- Workgroup - Athena workgroup
- Database - Athena database.
Importing Metadata
When connection was successful Dataedo will read objects and show a list of objects found. You can choose which objects to import. You can also use advanced filter to narrow down list of objects.
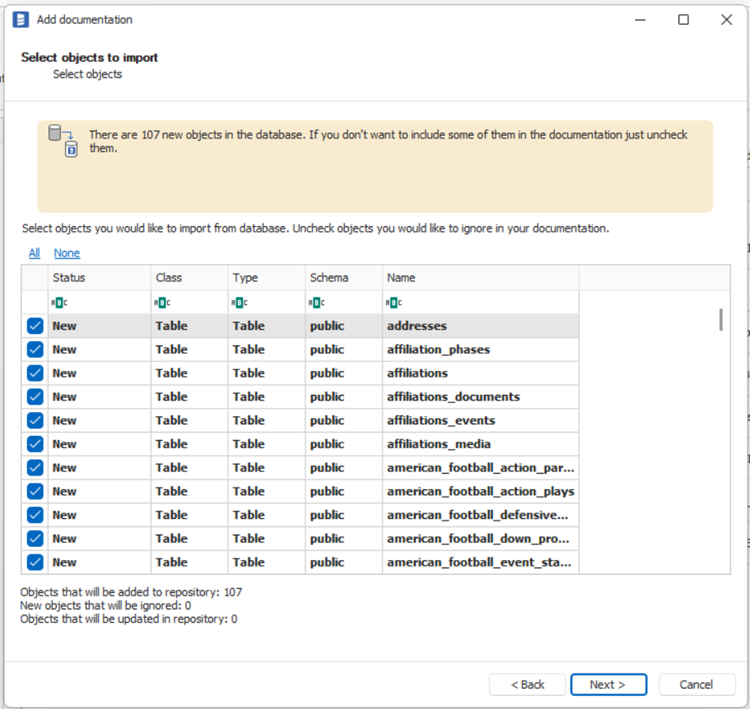
Confirm list of objects to import by clicking Next.
Next screen allow you to change default name of the documentation under which it will be visible in Dataedo repository.
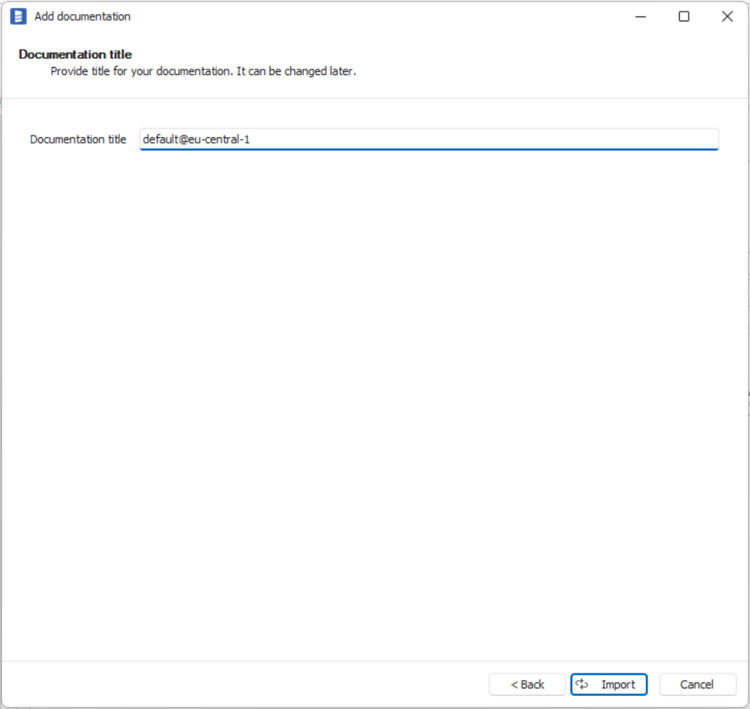
Click Import to start the import.
When done close import window with Finish button.
Outcome
Your Aws Glue Data Catalog database schema has been imported to new documentation in the repository.