







Connection requirements
To connect to Snowflake you need to install ODBC connector:
https://docs.snowflake.net/manuals/user-guide/odbc-download.html
Connecting to Snowflake
To connect to Snowflake create new documentation by clicking Add documentation and choosing Database connection.
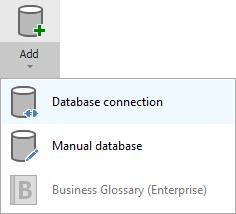
On the connection screen choose Snowflake as DBMS.
Select authentication mode:
- Password - you will need to provide username and password.
- SSO (browser) - Dataedo will open web browser to let you authenticate with Okta.
- JWT (private key) - authentication with a private key. Learn more
Provide database connection details:
- Host - provide a host name or address where a database is on. E.g. server17, server17.ourdomain.com or 192.168.0.37.
- Port - change the default port of Amazon Redshift instance if required
- User and password - provide your username and password
- Database - type in schema name
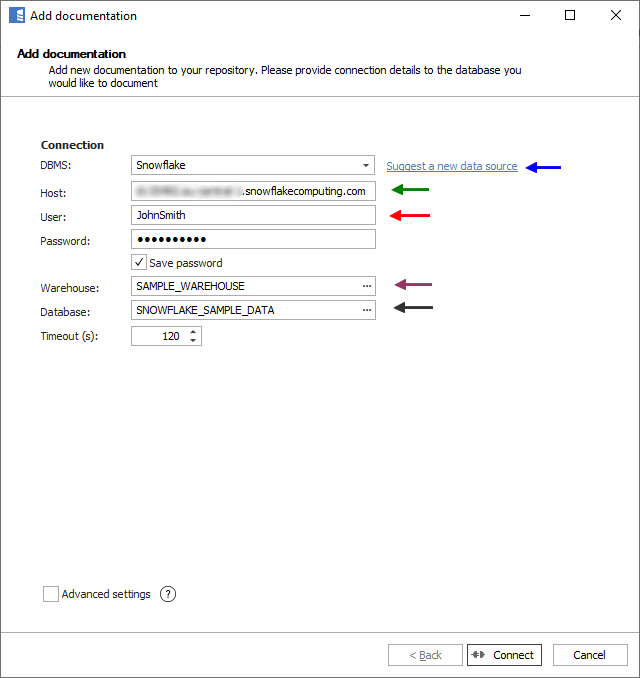
Here is a comparison with connection details in DBeaver.
Saving password
You can save password for later connections by checking Save password option. Password are saved in the repository database.
Importing schema
When connection was successful Dataedo will read objects and show a list of objects found. You can choose which objects to import. You can also use advanced filter to narrow down list of objects.
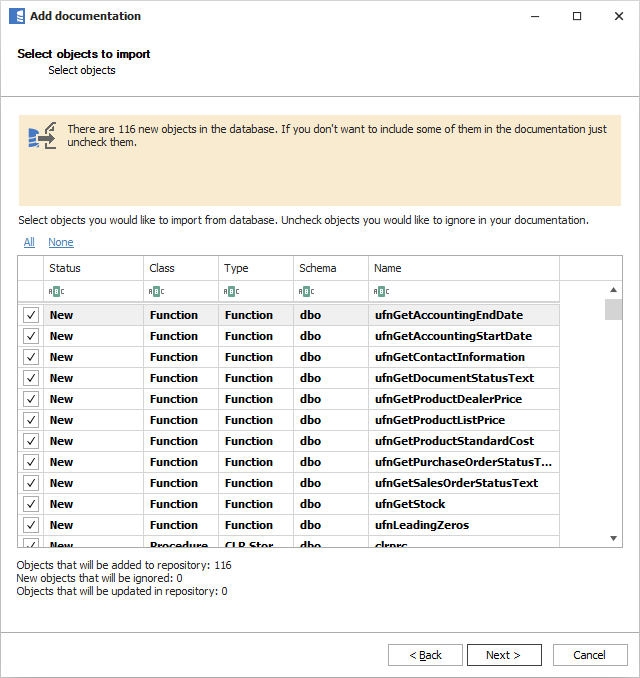
Confirm list of objects to import by clicking Next.
Next screen with allow you to change default name of the documentation under with your schema will be visible in Dataedo repository.
Click Import to start the import.
When done close import window with Finish button.
Your database schema has been imported to new documentation in the repository.

Importing changes
To sync any changes in the schema in Snowflake and reimport any technical metadata simply choose Import changes option. You will be asked to connect to Snowflake again and changes will be synced from the source.
Specification
Imported metadata
| Imported | Editable | |
|---|---|---|
| Tables, Transient tables | ✅ | ✅ |
| Columns | ✅ | ✅ |
| Data types | ✅ | ✅ |
| Nullability | ✅ | |
| Column comments | ✅ | ✅ |
| Table comments | ✅ | ✅ |
| Foreign keys | ✅ | ✅ |
| Primary keys | ✅ | ✅ |
| Unique keys | ✅ | ✅ |
| External tables, Iceberg tables | ✅ | ✅ |
| Location | ✅ | ✅ |
| Script | ✅ | ✅ |
| Columns | ✅ | ✅ |
| Data types | ✅ | ✅ |
| Nullability | ✅ | |
| Column comments | ✅ | ✅ |
| Table comments | ✅ | ✅ |
| Foreign keys | ✅ | ✅ |
| Primary keys | ✅ | ✅ |
| Views, Materialized Views | ✅ | ✅ |
| Script | ✅ | ✅ |
| Columns | ✅ | ✅ |
| Data types | ✅ | ✅ |
| Column comments | ✅ | ✅ |
| View comments | ✅ | ✅ |
| Dynamic tables | ✅ | ✅ |
| Script | ✅ | ✅ |
| Columns | ✅ | ✅ |
| Data types | ✅ | ✅ |
| Column comments | ✅ | ✅ |
| Table comments | ✅ | ✅ |
| Stored procedures | ✅ | ✅ |
| Script | ✅ | ✅ |
| Parameters | ✅ | ✅ |
| Procedure comments | ✅ | ✅ |
| Tasks | ✅ | ✅ |
| Script | ✅ | ✅ |
| Task comments | ✅ | ✅ |
| User-defined Functions | ✅ | ✅ |
| Script | ✅ | ✅ |
| Input arguments (all as a single field) | ✅ | ✅ |
| Output results (as a single field) | ✅ | ✅ |
| Function comments | ✅ | ✅ |
| Stages | ✅ | ✅ |
| Location | ✅ | ✅ |
| Stage comments | ✅ | ✅ |
| Pipelines | ✅ | ✅ |
| Script | ✅ | ✅ |
| Pipeline comments | ✅ | ✅ |
| Sequences | ✅ | ✅ |
| Streams | ✅ | ✅ |
| Columns | ✅ | ✅ |
| Script | ✅ | ✅ |
| Shared metadata | ||
| Dependencies | ✅ | ✅ |
| Created time | ✅ | |
| Last updated time | ✅ |
Comments
Dataedo reads comments from following Snowflake objects:
| Object | Read | Write back |
|---|---|---|
| Tables, Transient tables | ✅ | |
| Column comments | ✅ | |
| External tables, Iceberg tables | ✅ | |
| Column comments | ✅ | |
| Views, Materialized Views | ✅ | |
| Columns | ✅ | |
| Dynamic tables | ✅ | |
| Columns | ✅ | |
| Stored procedures | ✅ | |
| Tasks | ✅ | |
| Function | ✅ | |
| Stages | ✅ | |
| Pipelines | ✅ |
Data profiling
Datedo supports following data profiling in Snowflake:
| Profile | Support |
|---|---|
| Table row count | ✅ |
| Table sample data | ✅ |
| Column distribution (unique, non-unique, null, empty values) | ✅ |
| Min, max values | ✅ |
| Average | ✅ |
| Variance | ✅ |
| Standard deviation | ✅ |
| Min-max span | ✅ |
| Number of distinct values | ✅ |
| Top 10/100/1000 values | ✅ |
| 10 random values | ✅ |
Data Lineage
| Source | Method | Status |
|---|---|---|
| Views - object level | From dependencies | ✅ |
| Views - object level | From SQL parsing | ✅ |
| Views - column level | From SQL parsing | ✅ |
| Dynamic tables - object level | From INFORMATION_SCHEMA |
✅ |
| Dynamic tables - column level | From SQL parsing | ✅ |
| External storages (Azure, AWS) -> Stages | From INFORMATION_SCHEMA |
✅ |
| Stages -> External tables (Azure, AWS) | From INFORMATION_SCHEMA |
✅ |
| Stages -> Pipelines | From SQL parsing | ✅ |
| Pipelines -> Tables | From SQL parsing | ✅ |
| Stages -> Tables (COPY INTO) | FROM ACCOUNT_USAGE |
✅ |
| Table/View -> Streams | FROM ACCOUNT_USAGE |
✅ |
| Tables - from Kafka | TBD | TBD |
| dbt | dbt connector | ✅ |
Column-level data lineage is retived using Dataedo SQL parser. Read more about capabilities of Snowflake SQL parser.
Read more about Dataedo Snowflake data lineage.
Known limitations
- Snowflake’s
INFORMATION_SCHEMAcurrently doesn’t contain data on object dependencies or usage ofCOPY INTOstatements. Information about dependencies andCOPY INTOhistory is retrieved from theSNOWFLAKE.ACCOUNT_USAGE.OBJECT_DEPENDENCIESandSNOWFLAKE.ACCOUNT_USAGE.COPY_HISTORYviews. By default, theSNOWFLAKEdatabase is available only to theACCOUNTADMINrole. Read more about Enabling Snowflake Database Usage for Other Roles.
Due to Snowflake Connector for .NET limitations:
- Username and password
- Cannot contain ; and = characters
- Database, role and warehouse name
- Cannot contain ; and ‘ or \ characters
To import stream columns Dataedo requires access to SNOWFLAKE.ACCOUNT_USAGE.COLUMNS.
If one schema contains more than:
- 5000 foreign keys,
- or 6000 unique keys,
- or 10 000 primary keys,
then Dataedo will read those keys per object, not per schema - this will result in longer import time.
Learn more
Snowflake Enterprise Connector